We’re excited to share that we have just released a trio of new capabilities to the BigMLplatform. In this post, we’ll do a quick introduction to them followed by two more blog posts early next week that will dive deeper with some examples of how you can best utilize the new features. Without further ado, here they are.
New Data Connectors
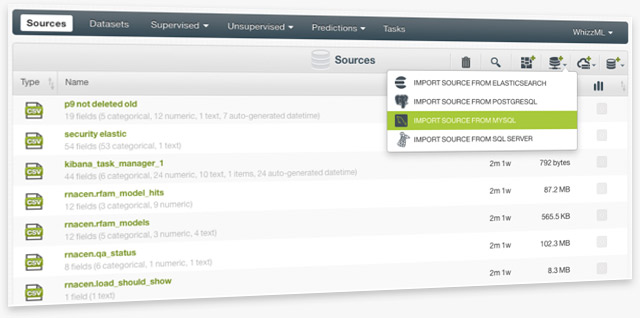
Every Machine Learning project starts with data and data can come from many sources. This is especially true for complex enterprise computing environments. Naturally, many BigML users look to import data directly from external databases to streamline Machine Learning workflows. No sweat, BigML now supports MySQL, SQL Server, Elasticsearch, and Spark SQL in addition to PostgreSQL.
Both the BigML Dashboard and the API allow you to establish a connector to your data store by providing relevant connection and authentication information, which are encrypted and stored in BigML for future access. BigML can then connect to your data store and immediately create the ‘Source’ in its server(s). You have the option to import data from individual tables or to do it selectively via custom queries by specifying data spanning multiple tables. Moreover, in an organization setting, administrators can easily create connectors to be used by other members of the same organization.
API Request Preview Configuration Option
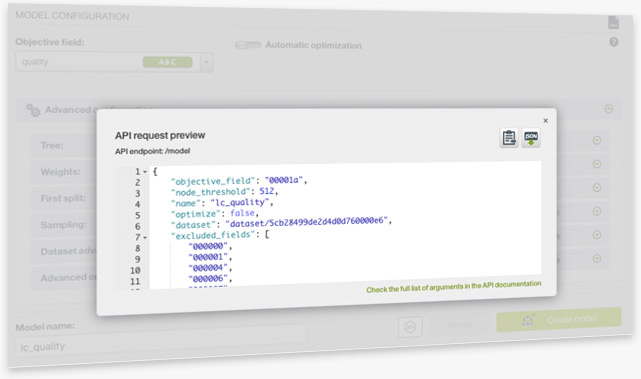
As a rule of thumb, anything you create on the BigML Dashboard, you can replicate with the BigML API. Now, BigML has added the ability to preview an API request as part of the configuration of unsupervised and supervised models — also available for Fusions on the Dashboard. This handy feature visually shows the user how to create a given resource programmatically including the endpoint for the REST API call as well as the corresponding JSON file that specifies the arguments to be configured.
WhizzML Scripting Enhancements in BigML Dashboard
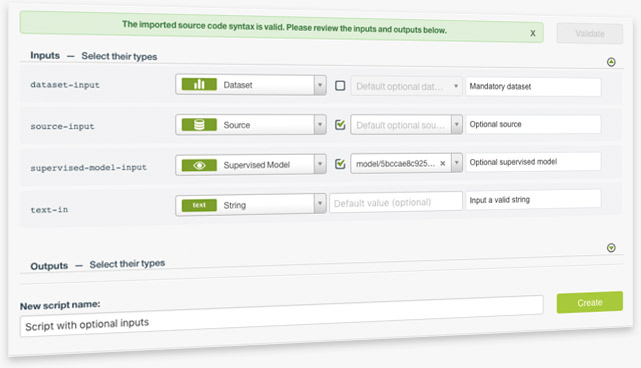
When you use WhizzML scripts, some inputs may be set as mandatory while others are optional. You may also provide default values to inputs. You can specify those in the corresponding JSON metadata files. Now, you can also do this on the BigML Dashboard when inputs are resources like Sources, Datasets, and Models. BigML provides checkboxes for users to easily toggle between those inputs, which can be set as mandatory or optional. Similarly, users also have the option to provide default values for those inputs or leave them empty in the BigML Dashboard.
Want to know more about these features?
If you have any questions or would like to find out how the above features work, please visit the release page. It includes useful links to the BigML Dashboard and API documentation already and we’ll add the links for the upcoming blog posts as we publish them.
