BigML has added multiple linear regression to its suite of supervised learning methods. In this sixth and final blog post of our series, we will give a rundown of the technical details for this method.
Model Definition
Given a numeric objective field
we model its response as a linear combination of our inputs
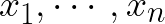
and an intercept value
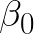

Simple Linear Regression
For illustrative purposes, let’s consider the case of a problem with a single input. We can see that the above expression then represents a line with slope
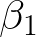
and intercept
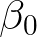
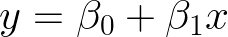
The task now is to find the values of
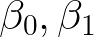
that parameterize a line which is the best fit for our data. In order to do so we must obtain a metric which quantifies how well a given line fits the data.

Given a candidate line, we can measure the vertical distance between the line and each of our data points. These distances are called residuals. Squaring the residual for each data point and computing the sum, we get our metric.
As one might expect, the sum of squared residuals is minimized when
define a line that passes more or less thorough the middle of the data points.
Multiple Linear Regression
When we deal with multiple input variables, it becomes more convenient to express the problem using vector and matrix notation. For a dataset with n rows and p inputs, define y as a column vector of length n containing the objective values, X as a n x p matrix where each row corresponds to a particular input instance, and
as a column vector of length p containing values of the regression coefficients. The sum of squared residuals can thus be expressed as:
The value of
which minimizes this is given by the closed-form expression:
The matrix inverse is the most computationally intensive portion of solving a linear regression problem. Rather than directly constructing the matrix X and performing the inverse, BigML’s implementation uses an orthogonal decomposition which can be incrementally updated with observed data. This allows for solving linear regression problems with datasets which are too large to fit into memory.
Predictions
Predicting new data points with a linear regression model is just about as easy as it can get. We simply take the coefficients
from the model and evaluate the regression equation above to obtain a predicted value for y. BigML also returns two metrics that describe the quality of the prediction: the confidence interval and the prediction interval. These are illustrated in the following figure:

These two intervals carry different meanings. Depending on how the predictions are to be used, one will be more suitable than the other.
The confidence interval is the narrower of the two. It gives the 95% confidence range for the mean response. If you were to sample a large number of points at the same x-coordinate, there is a 95% probability that the mean of their y values will be within this range.
The prediction interval is the wider interval. For a single point at the given x-coordinate, its y value will be within this range with 95% probability.
BigML Field Types and Linear Regression
In the regression equation, all of the input variables
are numeric values. Naturally, BigML’s linear regression model also supports categorical, text, and items fields as inputs. If you have seen how our logistic regression models handle these inputs, then this will be mostly familiar, but there are a couple important differences.
Categorical Fields
Categorical fields are transformed to numeric values via field codings. By default, linear regression uses a dummy coding system. For a categorical field with n class values, there will be n-1 numeric predictor variables x. We designate one class value as the reference value (by default the first one in lexicographic order). Each of the predictors corresponds to one of the remaining class values, taking a value of 1 when that value appears and 0 otherwise. For example, consider a categorical field with values “Red”, “Green”, and “Blue”. Since there are 3 class values, dummy coding will produce 2 numeric predictors x1 and x2. Assuming we set the reference value to “Red”, each class value produces the following predictor values:
| Field value | x1 | x2 |
|---|---|---|
| Red | 0 | 0 |
| Green | 1 | 0 |
| Blue | 0 | 1 |
Other coding systems such as contrast coding are also supported. For more details check out the API documentation.
Text and Items Fields
Text and items fields are treated in the same fashion. There will be one numeric predictor for each term in the tag cloud/items list. The value for each predictor is the number of times that term/item occurs in the input.
Missing Values
If an input field contains missing values in the training data then an additional binary-valued predictor will be created which takes a value of 1 when the field is missing and 0 otherwise. The value for all other predictors pertaining to the field will be 0 when the field is missing. For example, a numeric field with missing values will have two predictors: one for the field itself plus the missing value predictor. If the input has a missing value for this field, then its two predictors will be (0,1), in contrast, if the field is not missing, but equal to zero, then the predictors will be (0,0).
Wrap Up
That’s pretty much it for the nitty-gritty of multiple linear regression. Being a rather venerable machine learning tool, its internals are relatively straightforward. Nevertheless, you should find that it applies well to many real-world learning problems. Head over to the dashboard and give it a try!
