This guest post is originally authored by David Martínez, CEO at Ibim Building Twice S.L. and Pedro Núñez, I+D+I Manager at Ibim.
Building Information Modeling (BIM) is revolutionizing the construction industry. Unlike the data generated by computer-aided design (CAD), which represent flat shapes or volumes and 2D drawings consisting of lines, BIM data represent the reality of the built structure. This new way of digitizing the real world is superior in operational terms, and the structure of its data is ideal for analytical purposes and the application of Machine Learning techniques.
BigML enables BIM consultancies, Project Management Offices (PMO), construction companies, and developers to apply Machine Learning to BIM (even experimentally). Its user-friendly platform makes modeling possible without any in-depth knowledge of Machine Learning and enables previously unimaginable automated processes and knowledge.

Building Information Modeling uses data organized in a similar way to a database to create digital representations of real-life structures. BIM includes the geometry of the building, its spatial relationships and geographic information, and also the quantities and properties of its components. This information can be used to generate drawings and schedules that express the data in different ways.
The possibilities of applying Machine Learning techniques to BIM are countless. Classification algorithms, anomaly detection, and even time series analysis can be used with BIM. It is worth mentioning that BIM data are used throughout the lifespan of a building (i.e., during the design, construction, maintenance phases) and can even include real-life sensor data. This is a good example of how classification algorithms can be used by combining data from many buildings, the characteristics, and location of the flats to predict how well they might sell, or even the likelihood of construction delays. On the other hand, anomaly detection is very useful to pinpoint modeling errors, and with regards to time series analysis, we can apply it to real-time data to make better maintenance predictions.
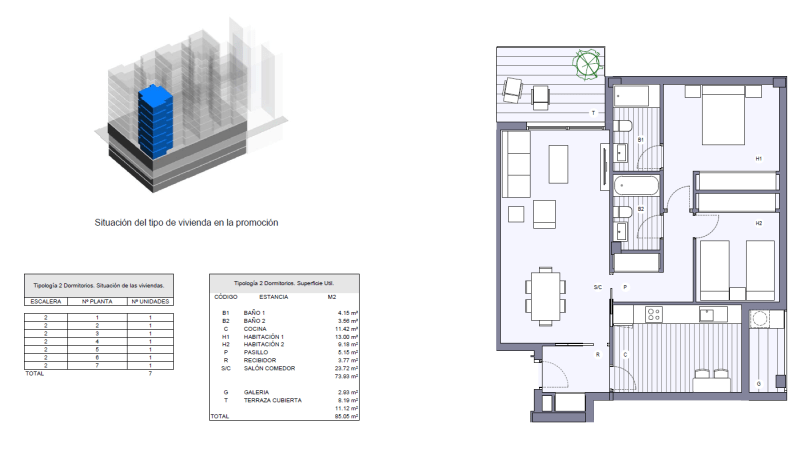
More specifically, Ibim Building Twice S.L. has conducted research into how the use of a room in a flat can be predicted based on its geometry and other BIM data. The findings are so remarkable that the company has decided to publish them as a contribution to the digitization of the construction industry. The different types of rooms in BIM are usually labeled entirely by hand by the expert modeler. The use of Machine Learning algorithms to automate this type of task could reduce the necessary time and outlay considerably. The experiment was based on data about residential buildings in BIM generated with Autodesk Revit®. The data about the rooms in the flats were extracted and re-processed using data schedules plus C# programming with the Revit API.
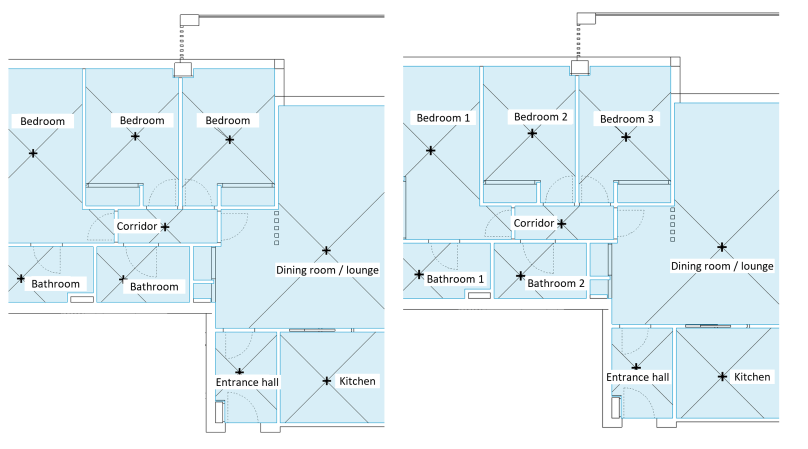
The extracted data were used as source data in BigML, which we first explored with dynamic scatterplots:
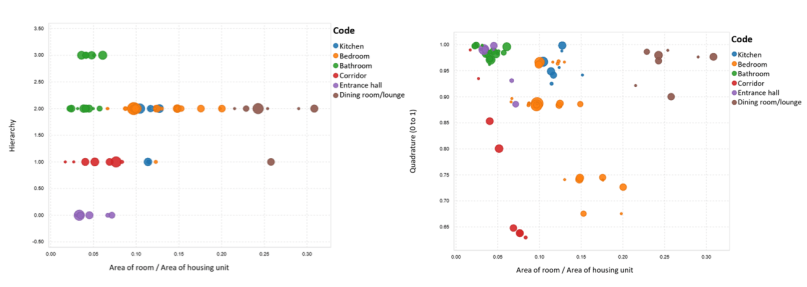
Later on, we created several structured data sets for training decision trees, logistic regressions, and deepnets, all of which are classification algorithms.
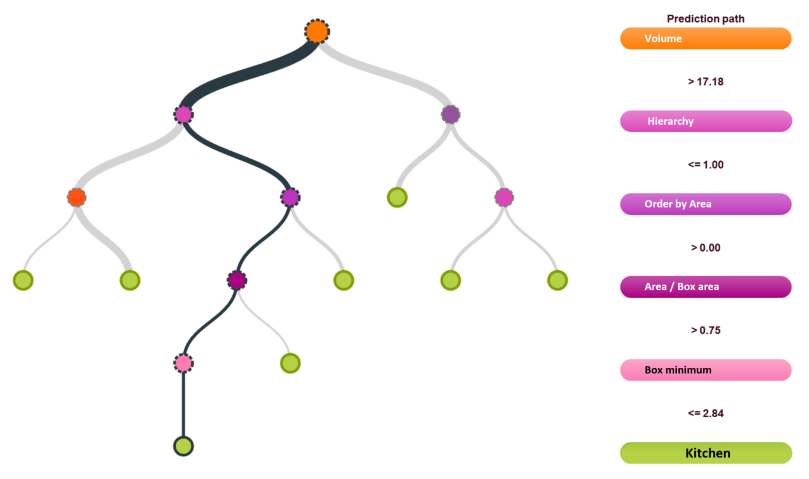
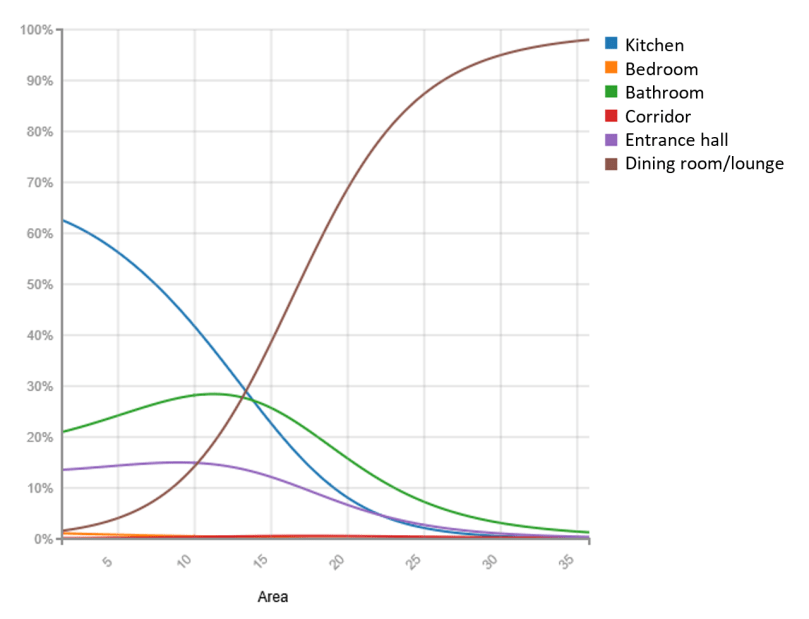
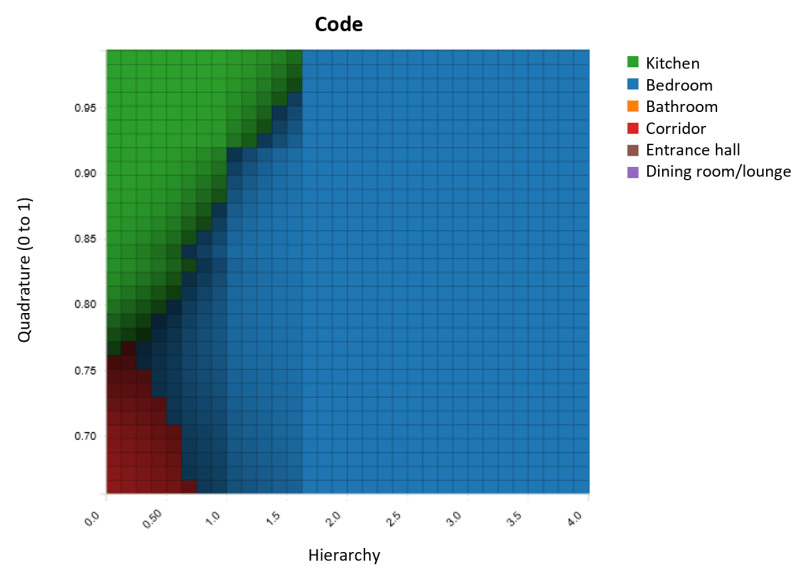
BigML makes it possible to measure the performance of each model easily. Although all three algorithms were used to solve the same problem (i.e., labelling rooms according to their function on the basis of their geometry and other data), the accuracy and suitability of the algorithms may vary considerably depending on the problem in hand, so it is advisable to evaluate them all in order to determine which one yields the best predictions.
In our experiment, the top models were about 90% accurate in predicting room use. Those were evaluated against data obtained from different architects and buildings, suggesting quite a promising technique for use in production. The findings of the study were presented at the EUBIM 2018 congress held in Valencia, on May 17-19, 2018. For more details, please watch the video of the presentation and check the corresponding slideshow and original article in English and Spanish that include full details of the experiment.

Best article, thanks for sharing information.
Fascinating post, thank you. I’m excited for machine learning to potentially automate new processes such as adding reality capture data into BIM plans, saving even more time and money.