BigML Associations can help identify which pairs (or groups) of items occur together more frequently than expected. A typical use case for association rule discovery is market basket analysis, where the goal is to find the products that are usually purchased together by customers.
BigML’s Associations is able to output such interesting associations from your dataset as rules, which are expressed as a combination of fields and their values. The field values for which you want to find the associations can be either be arranged in different fields (when the number of elements per instance is fixed), or they can be stored all together in a unique field. This latter field format is referred to as an items field in BigML and it allows for multiple values per instance separated by a designated separator. Let’s take a look at a related dataset example.
![]()
Source Data
For this blog post, we are going to use a Kaggle dataset about orders and products from the Instacart Market Basket Analysis competition.
The data in this competition is provided in multiple sources or files. In total, there are five different sources: Aisles, Departments, Orders, Products, and Order_Products. You can take a look at each file description on the Instacart Kaggle competition page.
ML-Ready Dataset Definition
To discover associations between products purchased in the same order with BigML, we need to transform the source data and build a dataset where every row must be a unique order that also contains a multi-value field with all the products purchased together in the same order. This is our items field in BigML, where each element or item needs to be separated by the same separator. In the example below, each product is separated by a pipe in the “Products” field.
Order_id Products 992312 Milk|Sugar|Biscuits|Orange Juice|Beans 532529 Lettuce|Tomatoes 392342 Bread|Cooked ham|Vinegar|Olive oil|Toilet paper ...
Transformations
To build the ML-ready dataset described above, we only need three sources, Orders, Order_Products and Products. First of all, we’ll import the source files into a relational database like MySQL to be able to analyze and work with data.
drop table if exists imp_products; create table imp_products ( `product_id` int, `product_name` varchar(256), `aisle_id` int, `department_id` int, primary key (`product_id`)); load data infile 'products.csv' into table imp_products fields terminated by ',' enclosed by '"' lines terminated by '\n' ignore 1 lines (@product_id,product_name,@aisle_id,@department_id) set `product_id` = nullif(@product_id,''), `aisle_id` = nullif(@aisle_id,''), `department_id` = nullif(@department_id,''); drop table if exists imp_orders; create table imp_orders ( `order_id` int, `user_id` int, `eval_set` varchar(16), `order_number` int, `order_dow` int, `order_hour_of_day` int, `days_since_prior_order` double(16,2), primary key (`order_id`)); load data infile 'orders.csv' into table imp_orders fields terminated by ',' enclosed by '"' lines terminated by '\n' ignore 1 lines (@order_id,@user_id,eval_set,@order_number,@order_dow,@order_hour_of_day,@days_since_prior_order) set `order_id` = nullif(@order_id,""),`user_id` = nullif(@user_id,""),`order_number` = nullif(@order_number,""),`order_dow` = nullif(@order_dow,""),`order_hour_of_day` = nullif(@order_hour_of_day,""),`days_since_prior_order` = nullif(@days_since_prior_order,""); drop table if exists imp_orders_products; create table imp_orders_products ( `order_id` int, `product_id` int, `add_to_cart_order` int, `reordered` int, primary key (`order_id`,`product_id`)); load data infile 'order_products__train.csv' into table imp_orders_products fields terminated by ',' enclosed by '"' lines terminated by '\n' ignore 1 lines (@order_id,@product_id,@add_to_cart_order,@reordered) set `order_id` = nullif(@order_id,""), `product_id` = nullif(@product_id,""), `add_to_cart_order` = nullif(@add_to_cart_order,""), `reordered` = nullif(@reordered,""); load data infile 'order_products__prior.csv' into table imp_orders_products fields terminated by ',' enclosed by '"' lines terminated by '\n' ignore 1 lines (@order_id,@product_id,@add_to_cart_order,@reordered) set `order_id` = nullif(@order_id,""), `product_id` = nullif(@product_id,""), `add_to_cart_order` = nullif(@add_to_cart_order,""), `reordered` = nullif(@reordered,""); create index inx_impordprods_ordadd on imp_orders_products (`order_id`,`add_to_cart_order`);
Once the data is imported into MySQL tables, we can work easily with them. To build a dataset like the objective described previously, we’ll execute this code.
# ML-Ready dataset
drop table if exists orders;
create table orders (
`order_id` int,
`products` text,
primary key (`order_id`));
# Extract different order_id's
insert into orders (`order_id`) select `order_id` from imp_orders where `eval_set` in ('prior','train');
# Calculate the Products field concatenating all the product_names foreach Order
update orders a set `products` = (
select group_concat(b.`product_name` order by c.`add_to_cart_order` separator "|")
from imp_products b, imp_orders_products c
where c.`order_id` = a.`order_id` and
b.`product_id` = c.`product_id`
group by c.`order_id`);
With that, the ML-ready table is already calculated and filled with the real values. We just need to generate a CSV file from of this table and upload it to BigML.
# CSV generation \! rm -f mlr_orders.csv select "order_id","products" union all select `order_id`,`products` into outfile 'mlr_orders.csv' fields terminated by ',' optionally enclosed by '"' escaped by '\\' lines terminated by '\n' from orders; \! perl -pi -e 's/\\N//g' mlr_orders.csv \! perl -pi -e 's/\\\"/\"\"/g' mlr_orders.csv
Training the Association Discovery
When we upload the CSV file to BigML, a source is automatically created and the field types are correctly identified: numeric for the order_id, and items for the products field (being the items separator the pipe). In case you don’t agree with BigML chosen data types you can always override them, but we don’t need that here.
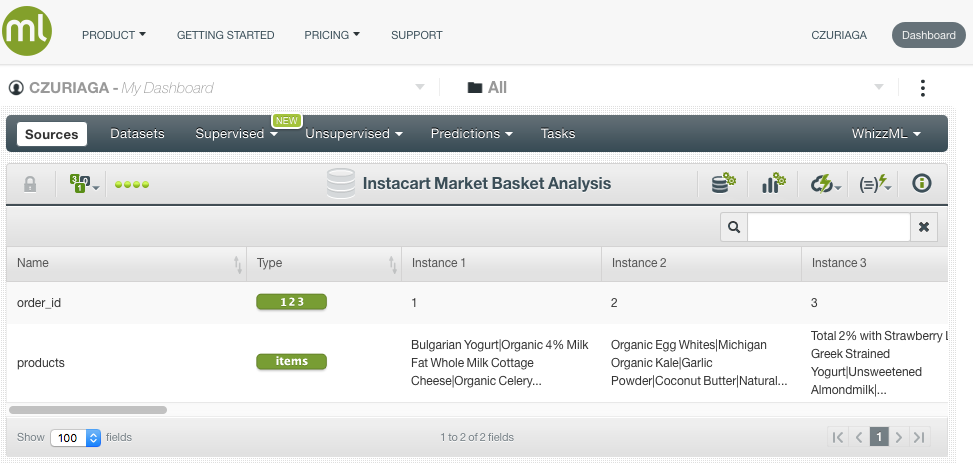
From the source, in a single click, we can generate a dataset, which is a structured version of the data that can be used by a BigML Machine Learning algorithm.
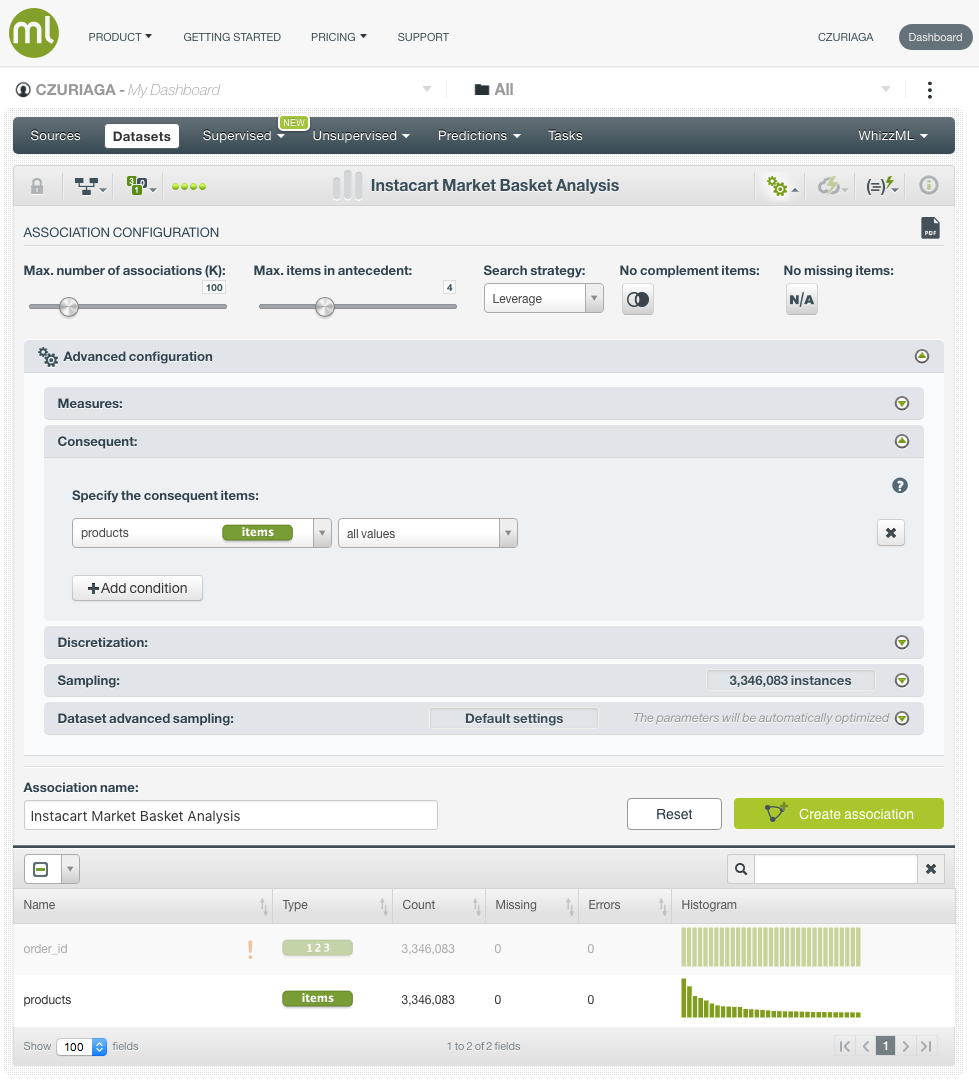
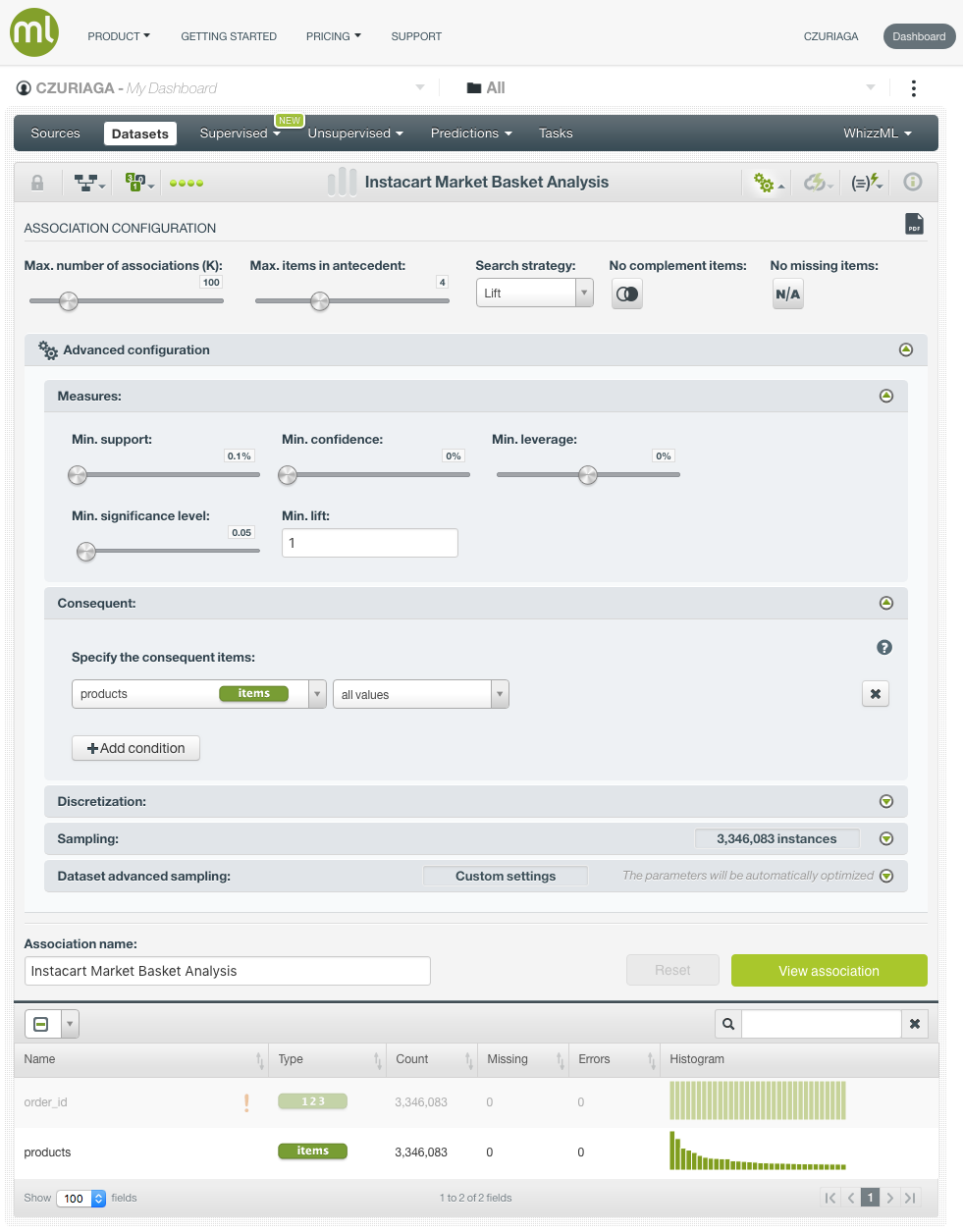
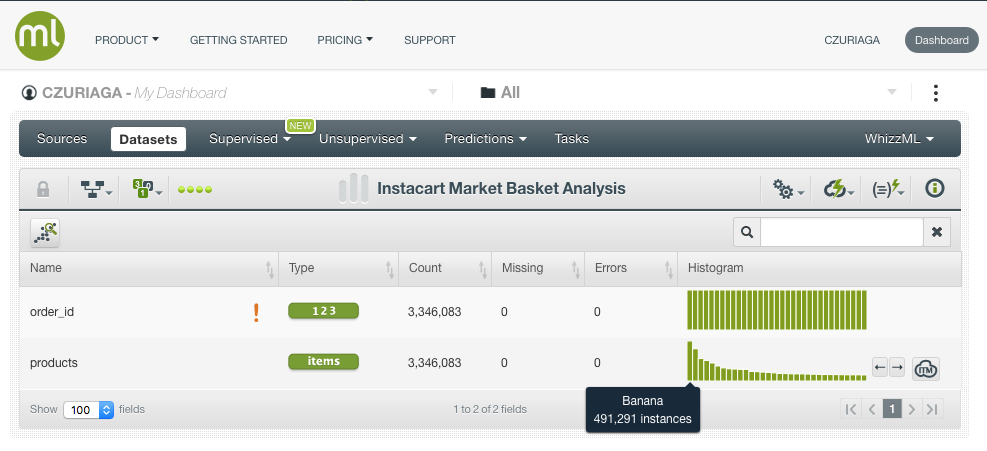 Next, we generate an Association to find the products that are usually purchased together. Associations can be configured in multiple ways. By default, the search strategy is Leverage (the difference between the probability of the rule and the expected probability were the items statistically independent).
Next, we generate an Association to find the products that are usually purchased together. Associations can be configured in multiple ways. By default, the search strategy is Leverage (the difference between the probability of the rule and the expected probability were the items statistically independent).
It seems that the strongest rules found using this search strategy, are related to organic products.
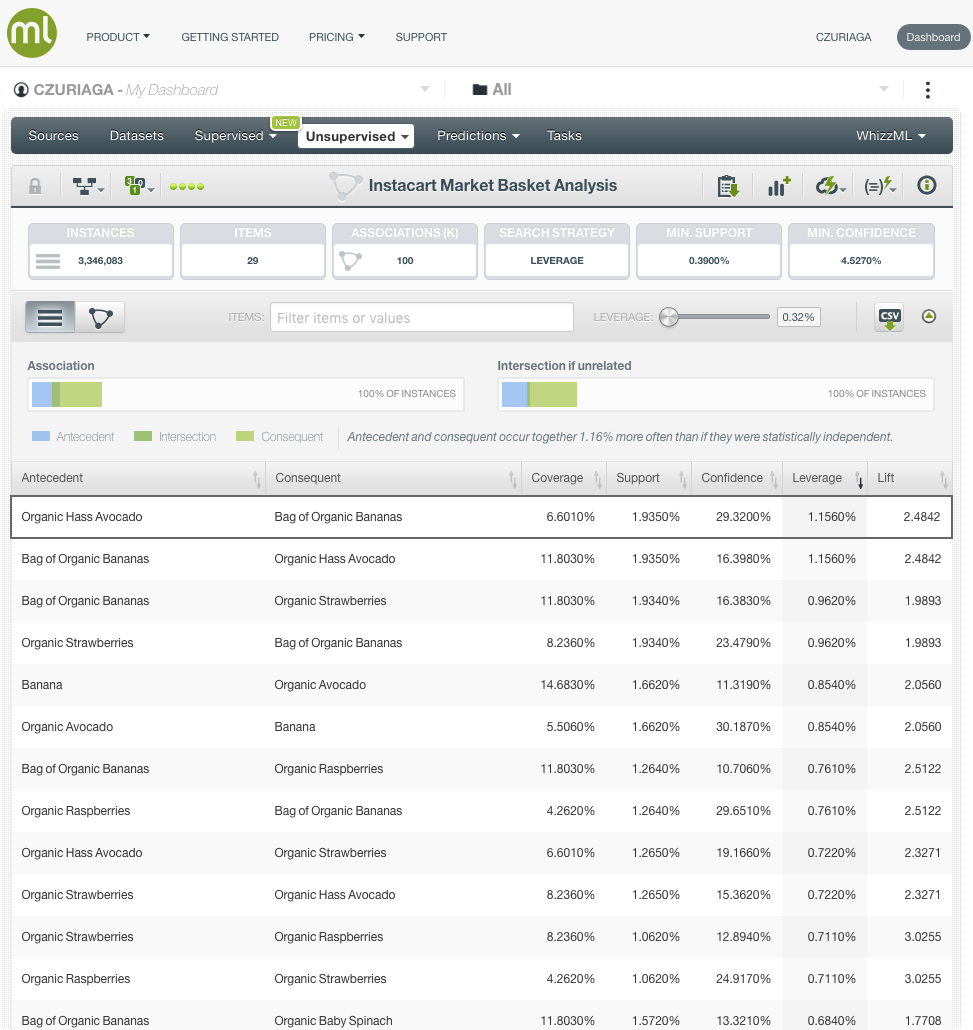
- Organic Hass Avocado <—-> Bag of Organic Bananas
- Organic Strawberries <—-> Bag of Organic Bananas
- Organic Raspberries <—-> Bag of Organic Bananas
- etc.
There are also other types of search strategies when building an Association Discovery. If we want to find relationships between unusual products, using Lift (how many times more often the antecedent and consequent occur together than expected were they statistically independent), and forcing a minimum support of 0.1%, the resulting rules in the new Association, are quite different.
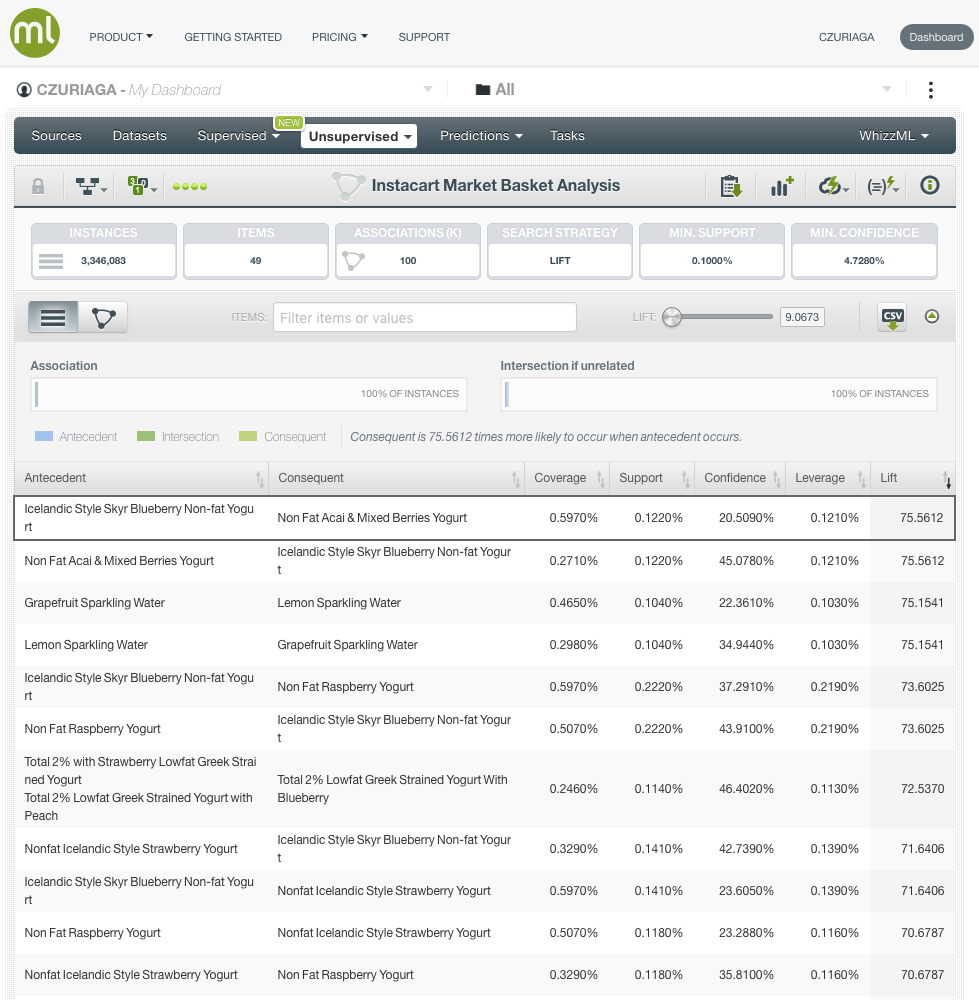
- Icelandic Style Skyr Blueberry Non-fat Yogurt <—-> Non-Fat Acai & Mixed Berries Yogurt
- Grapefruit Sparkling Water <—-> Lemon Sparkling Water
- Sparkling Water Grapefruit + Sparkling Lemon Water —-> Lime Sparkling Water
- Zero Calorie Cola <—-> Soda
- etc.
That’s it! In this blog post, we’ve described how to construct a ML-Ready dataset for BigML Associations from different source files. We also found out about different ways to build Associations between products. Now it’s your turn to give it a spin and let us know of your feedback!
