Everyone knows TED talks. TED started in 1984 as a conference series on technology, education, and design. In essence, TED talks aim to democratize knowledge. Nowadays it produces more than 200 talks per year addressing dozens of different topics. Despite the critics who claim that TED talks reduce complex ideas to 20-minute autobiographical stories of inspiration, the great influence they have on the knowledge diffusion in our society is undeniable.
When I came across the TED dataset in Kaggle, the first thing that caught my attention was the great dispersion in the number of views: from 50K to over 47M (with a median of ~1M views). One can’t keep but wonder what makes some talks 20 times more popular than others? Can the TED organizers and speakers do something to maximize the views in advance? In this blog post, we’ll try to predict the popularity of TED talks and analyze the most influential factors.
The Data
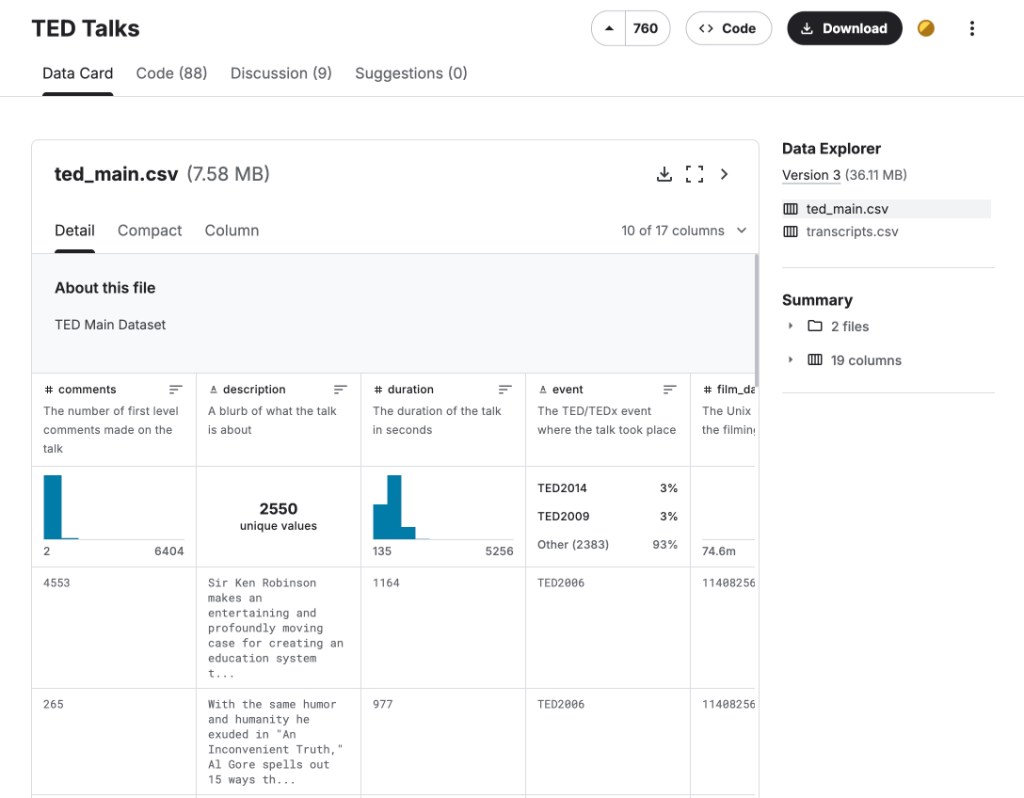
The original file provides information for 2,550 talks over one decade: from 2006 (only 50 talks were published) until 2017 (over 200 talks were published). When you create a dataset in BigML, you can see all the features with their types and their distributions. You can see the distribution of talks over the years in the last field in the dataset seen below.
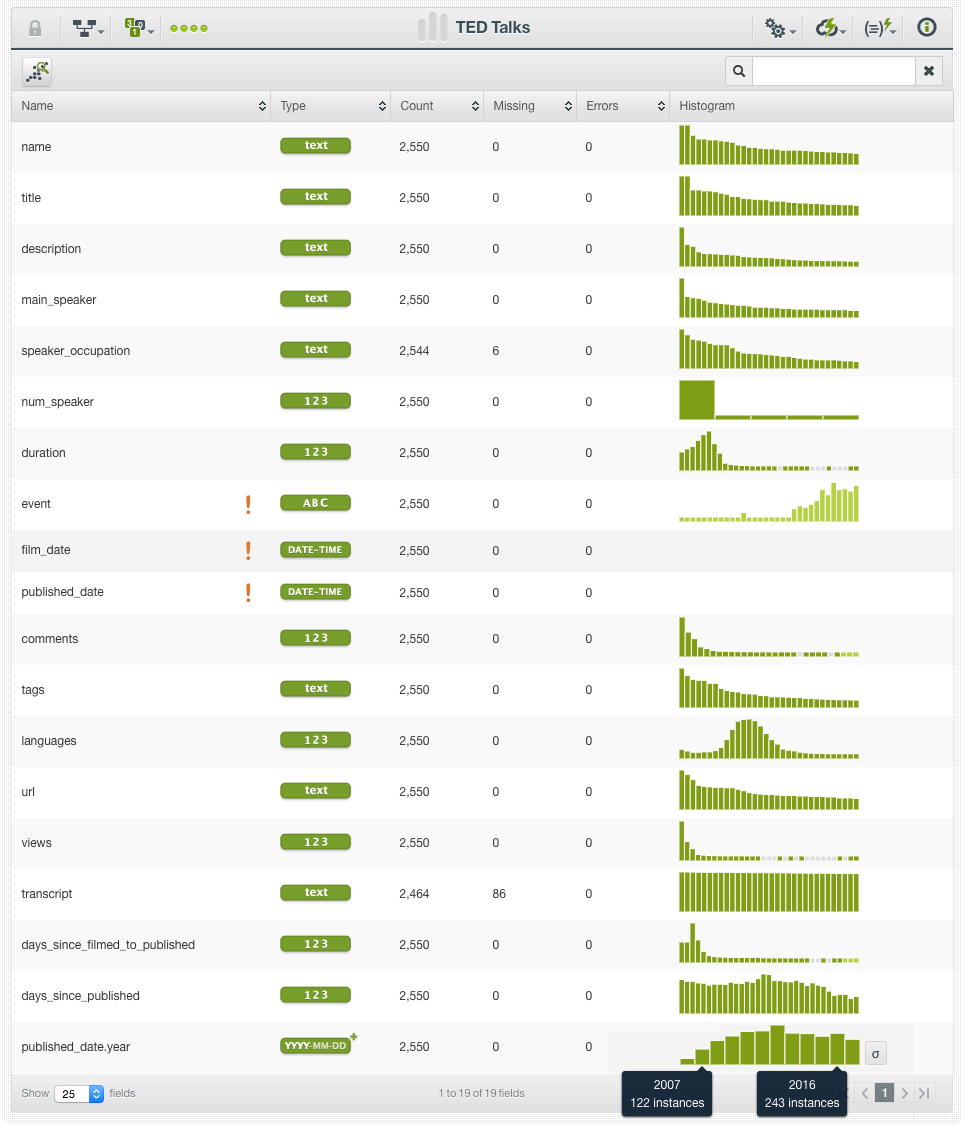
For text fields, we can inspect the word frequency in a tag cloud. For example, the most used words in the titles are “world”, “life” and “future”.
When we take a look at the features, we see two main sets: one that informs us about the talk impact (comments, languages, and views -our objective field-), and another that describes the talk characteristics (the title, description, transcript, speakers, duration, etc). Apart from the original features, we came up with two additional ones: the days between video creation and publishing and the days between publishing and dataset collection on Sept 21, 2017.
The fields related to talk impact may be a future consequence of our objective field: the views. A talk with more views is more likely to have a higher number of comments and to be translated into more languages. Therefore, it’s best if we exclude those from our analysis, otherwise, we will create a “leakage”, i.e., leaking information from the future in the past, thus obtaining unrealistically good predictions.
On the other hand, all the fields related to the talk characteristics can be used as predictors. Most of them are text fields such as the title, the description, or the transcript. BigML supports text fields for all supervised models, so we can just feed the algorithms with them. However, we suspect that not all the thematically related talks necessarily use the same words. Thus, using the raw text fields may not be the best way to find patterns in the training data that can be generalized to other TED talks. What if instead of using the exact raw words in the talks, we could extract their main topics and use them as predictors? That is exactly what BigML topic models allow us to do!
Extracting the Topics of TED talks
We want to know the main topics of our TED talks and use them as predictors. To do this, we build a topic model in BigML using the title, the description, the transcript, and the tags as input fields.
The coolest thing about BigML topic models is that you don’t need to worry about text pre-processing. It’s very hand that BigML automatically cleans the punctuation marks, homogenizes the cases, excludes stopwords, and applies stemming during the topic model creation. You can also fine tune those settings and include bigrams as you wish by configuring your topic model in advance.
When our topic model is created, we can see that BigML has found 40 different topics in our TED talks including technology, education, business, religion, politics, and family, among others. You can see all of them in a circle map visualization in which each circle represents a topic. The size of the circle represents the importance of that topic in the dataset and related topics are located closer in the graph. Each topic is a distribution over term probabilities. If you mouse over each topic you can see the top 20 terms and their probabilities within that topic. BigML also provides another visualization in which you can see all the top terms per topic displayed in horizontal bars. You can observe both views below or better yet inspect the model by yourself here!

BigML topic models are an optimized implementation of Latent Dirichlet Allocation (LDA), one of the most popular probabilistic methods for topic modeling. If you want to learn more about topic models, please read the documentation.
All the topics found seem to be coherent with main TED talks themes. Now we can use this model to calculate the topic probabilities for any new text. Just click on the option Topic Distribution in the 1-click action menu, and you will be redirected to the prediction view where you can set new values to your input fields. See below how the distribution over topics changes when you change the text in the input fields.

Now we want to do the same for our TED talks. To calculate the topic probabilities for each TED talk we use the option Batch Topic Distribution in the 1-click action menu. Then we select our TED talks dataset. We also need to make sure that the option to create a new dataset out of the topic distribution is enabled!
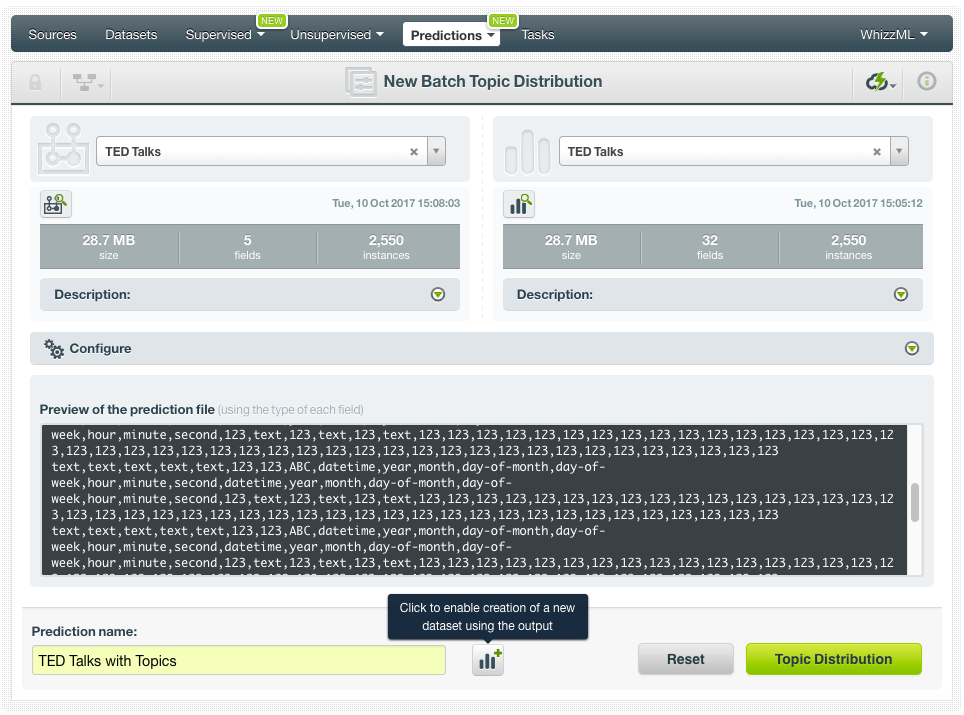
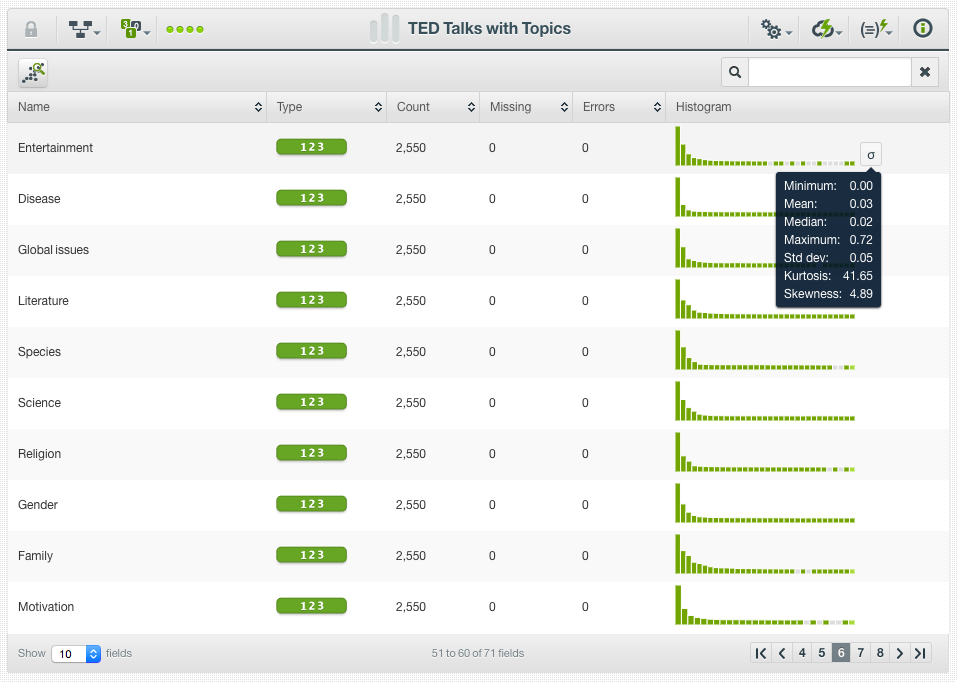
When the batch topic distribution is created, we can find the new dataset with additional numeric fields, containing the probabilities of each topic per TED talk. These are the fields that we will use as inputs to predict the views replacing the transcript, title, description, and tags.
Predicting the TED Talks Views
Now we are ready to predict the talk views. As we mentioned at the beginning of this post, the number of talks is a widely dispersed and highly skewed field, therefore predicting the exact number of views can be difficult. In order to find more general patterns of the influence of topics as applicable to the talks popularity, we are going to discretize the views and make it categorical. This is very easy in BigML, you just need to select the option to Add fields to the dataset in the configure option menu. We are going to discretize the field by percentiles by using the median.
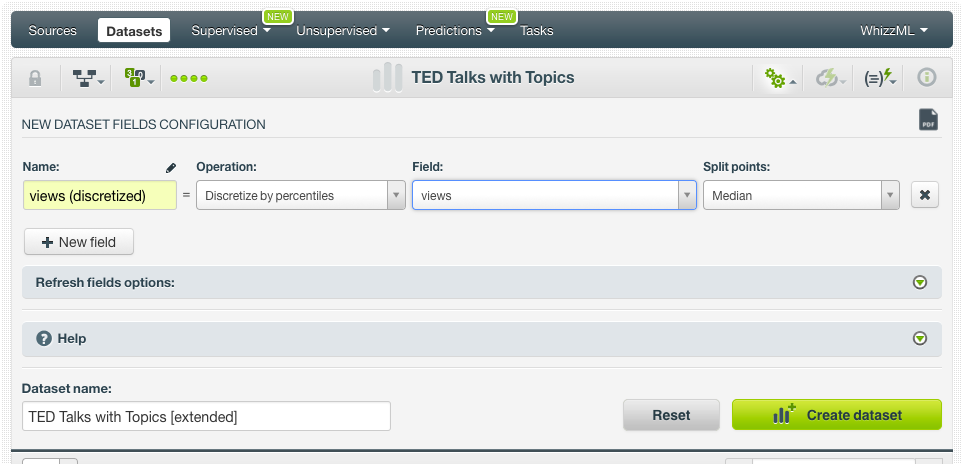
Then we click the button to create a dataset. The dataset contains a new field with two classes, the first class containing the talks below the median number of views (less than 1M views), and a second class containing the talks over the median number of views, (more than 1M views).
Before creating our classification model, we need to split our dataset into two subsets: the 80% for training and the remaining 20% for testing to ensure that our model generalizes well against data that the model has not seen before. We can easily do this in BigML by using the corresponding option in the 1-click action menu, as shown below.
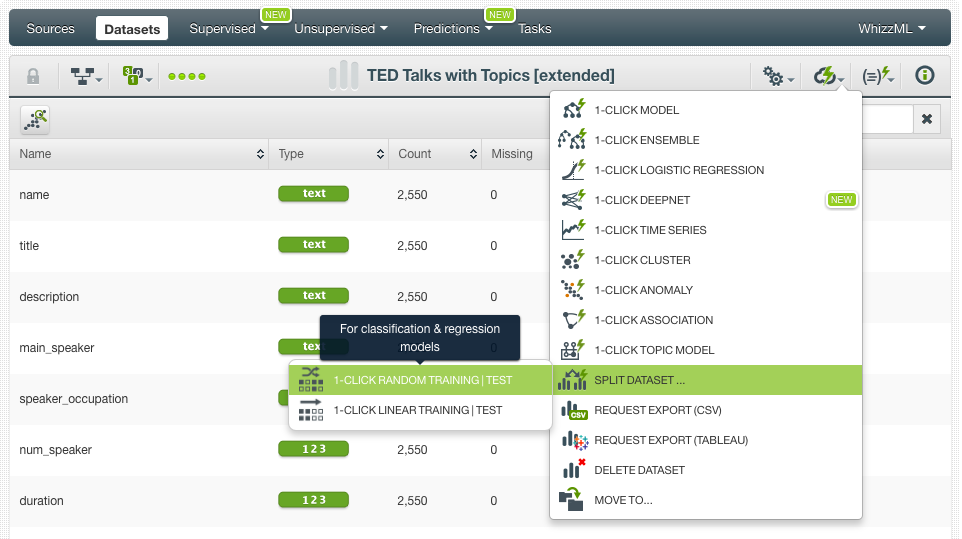
We proceed with the 80% of our dataset to create our predictive model. To compare how different algorithms perform, we create a single tree, an ensemble (Random Decision Forest), a logistic regression and the latest addition to BigML, deepnets (an optimized implementation of the popular deep neural networks). You can easily create those models from the dataset menus. BigML automatically selects the last field in the dataset as the objective field “views (discretized)” so we don’t need to configure it differently. Then we use the 1-click action menu to easily create our models.
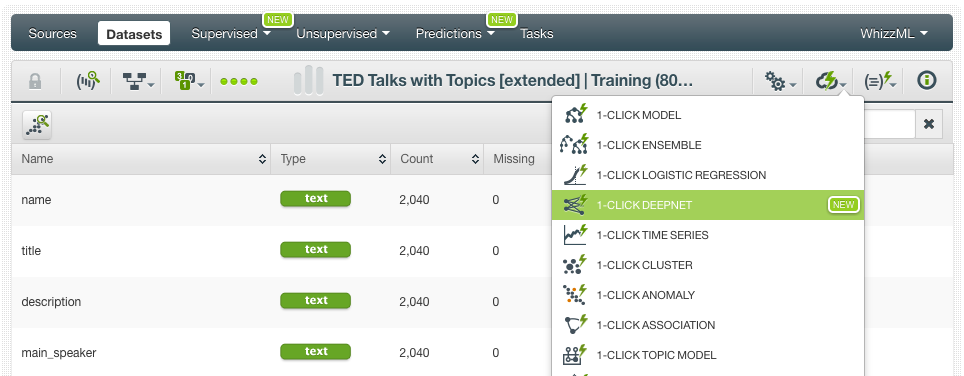
Apart from the 1-click deepnet, which uses an automatic parameter optimization option called Structure Suggestion, we also create another deepnet by configuring an alternative automatic option called Network Search. BigML offers this unique capability for automatic parameter optimization to eliminate the difficult and time-consuming work of hand-tuning your deepnets.
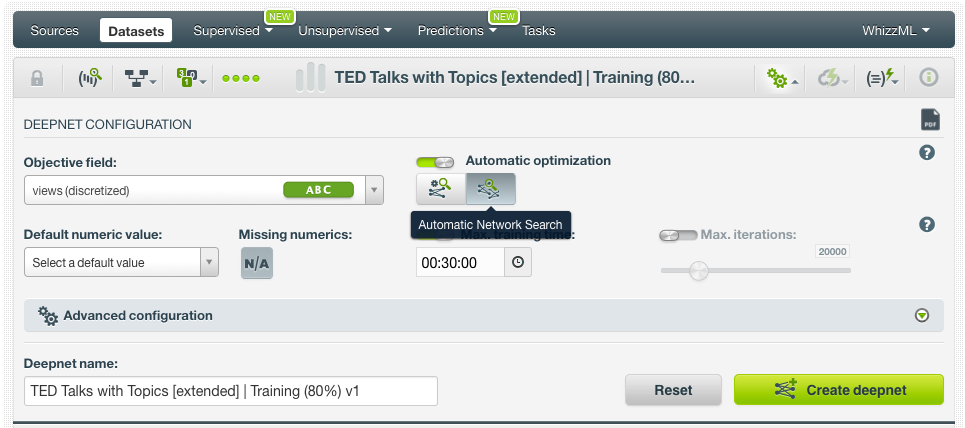
After some iterations, we realize that the features related to the speaker have no effect on the number of views, therefore we eliminate those along with the field “event” that seems to be causing overfitting. At the end, we use as input fields all the topics, the year of the published date, the duration of the talk, plus our calculated field that measures the number of days since the published date (until the 21st of Sept 2017).
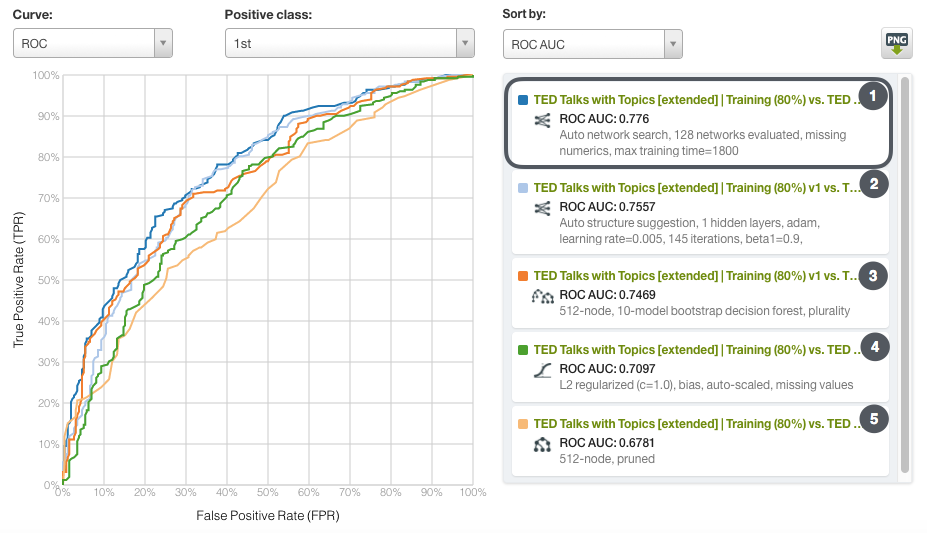
After creating all the models with these selected features, we need to evaluate them by using the remaining 20% of the dataset that we set aside earlier. We can easily compare the performance of our models with the BigML evaluation comparison tool, where the ROC curves can be analyzed altogether. As seen below, the winner with the highest AUC (0.776) is a deepnet that uses the automatic parametrization option “Network Search”. The second best performing model is again a deepnet, but the one using the automatic option “Structure Suggestion”. This one has a AUC value of 0.7557. In third place, we see the ensemble (AUC of 0.7469), followed by logistic regression (AUC of 0.7097) and finally the single tree (AUC of 0.6781).
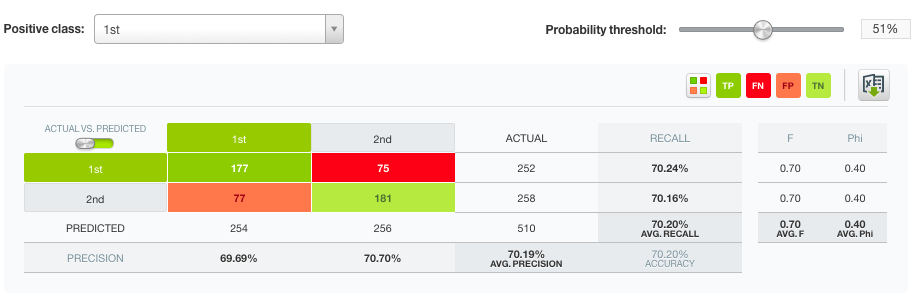
When we take a look at the confusion matrix of our top performing deepnet, we can see that we are achieving over 70% recall with a 70% precision for both classes of the objective field.
Inspecting the Deepnet
Usually, deep neural network predictions are hard to analyze, that’s why BigML provides ways to make it easy for you to understand why your model is making particular decisions.
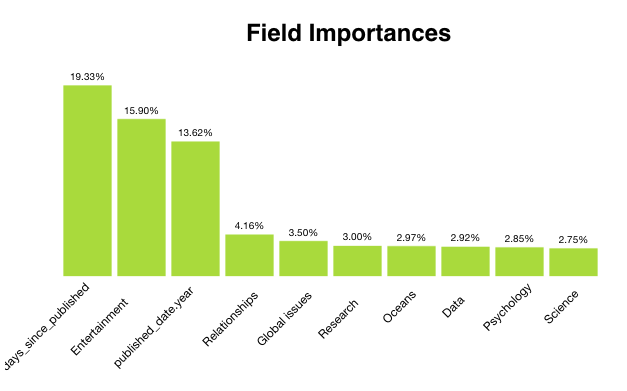
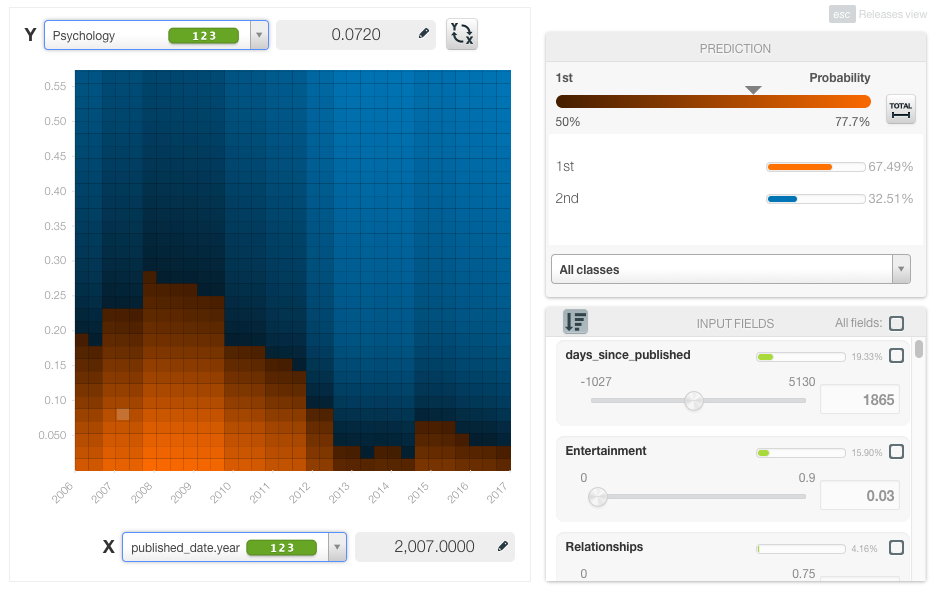
First, BigML can tell us which fields are most important in predicting the number of views. By clicking on the “Summary Report” option, we get a histogram with a percentage per field that displays field importances. We can see that (not surprisingly) the “days_since_published” is the most important field (19.33%), followed by the topic “Entertainment” (15.90%), and the “published_date.year” (13.62%). Amongst the top 10 most important fields we can also find the topics “Relationships”, “Global issues”, “Research”, “Oceans”, “Data”, “Psychology” and “Science”.
Great! We can state that our deepnet found the topics as relevant predictors in deciding the number of views. But how exactly do these topics impact predictions? Will talks about psychology have more or less views than talks about science? To answer this question, BigML provides a Partial Dependence Plot view, where we can analyze the marginal impact of the input fields on the objective field. Let’s see some examples (or play with the visualization here at your leisure).
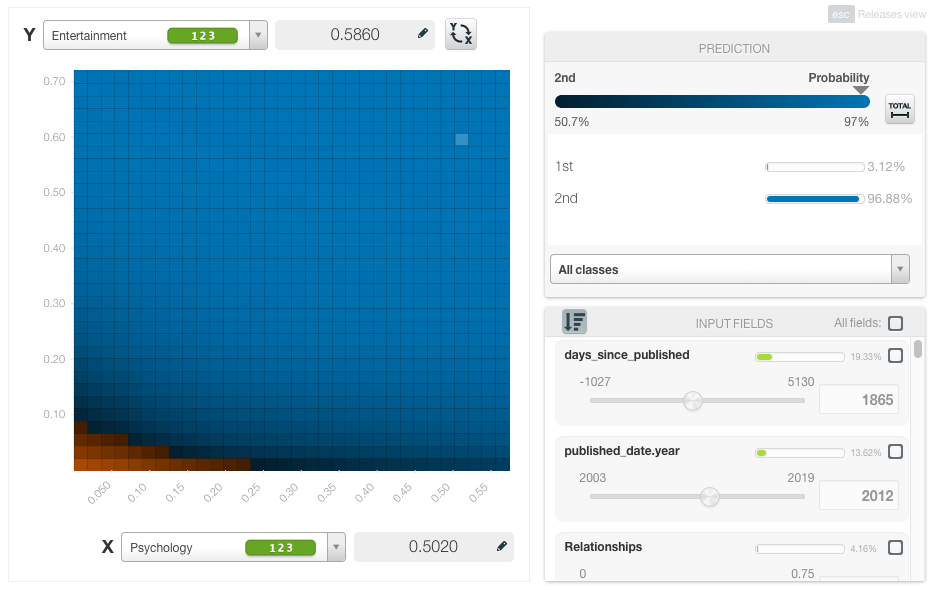
For example, see in the image below how the combination of the topics “Entertainment” and “Psychology” have a positive impact on the number of views. Higher probabilities of those topics result in the prediction of our 2nd class (the blue one), which is the class over 1M number of views.
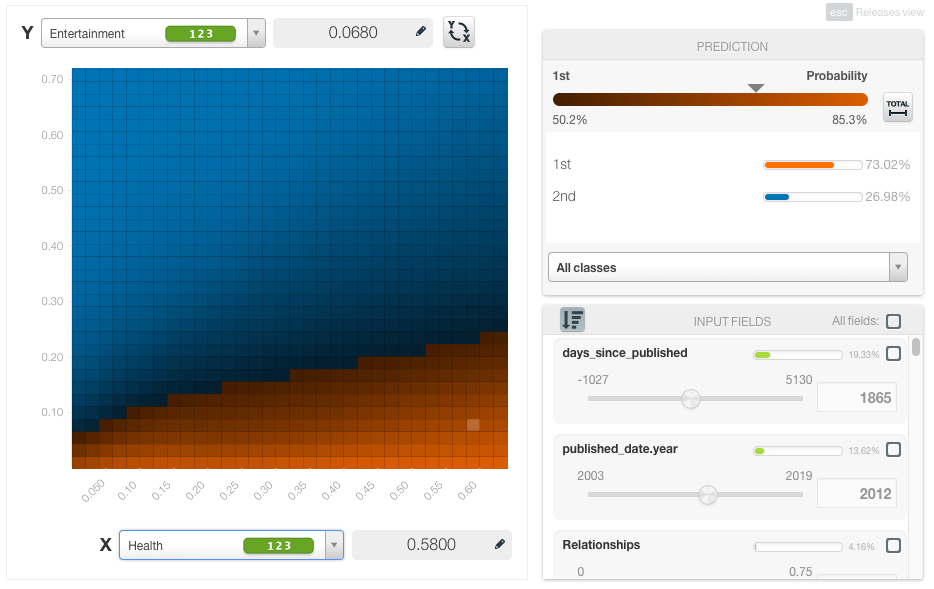
On the contrary, if we select “Health” instead, we can see how higher probabilities of this topic result in a higher probability of predicting the 1st class (the class below 1M number of views).
We can also see a change over time in the interest in some topics. As you can see below, the probability of the psychology topic to have more than 1M views has increased in the recent years given the period of 2012 to 2017.
Conclusions
In summary, we have seen that topics do have a significant influence on the number of views. After analyzing the impact of each topic in predictions, we observe that “positive” topics such as entertainment or motivation are more likely to have a greater number of views while talks with higher percentages of the “negative” topics like diseases, global issues or war are more likely to have fewer views. In addition, it seems that the interest in individual human-centered topics such as psychology or relationships has increased over the years to the detriment of broader social issues like health or development.
We hope you enjoyed this post! If you have any questions don’t hesitate to contact us at support@bigml.com.
