Raw information is useless if you don’t understand what it means, but sometimes there is just so much it’s hard to get a handle on what is going on. One way to better understand your data is through cluster analysis – grouping similar data in “clusters”. At BigML we use a centroid-based clustering to group your data with just one click. While this is terribly convenient, it can obscure how the clustering decisions are actually made. When a dataset has dozens of input fields (or more!), how can you tell which ones were actually important in grouping your data?

What is important anyway?
This is a really big question, but at BigML we specialize in turning big questions into answers. Here something is important to a process if it affects the outcome of that process. For example, consider the importance of an input field when building a decision tree. A BigML decision tree automatically finds the importance of each input field by finding every time an input field was used to make a split in the tree and then averaging how different the prediction would have been without that split. With this definition of importance, more is better. While a single tree may give some understanding of which fields are important, a whole forest of trees would give even more certainty that the most important fields are identified.
How can we apply this definition of importance to the case of clusters? If one of the input fields was which cluster the datapoint belonged to, we could build a model to predict that field. Find the importance of other input fields in this model, and that would give their importance to deciding cluster membership.
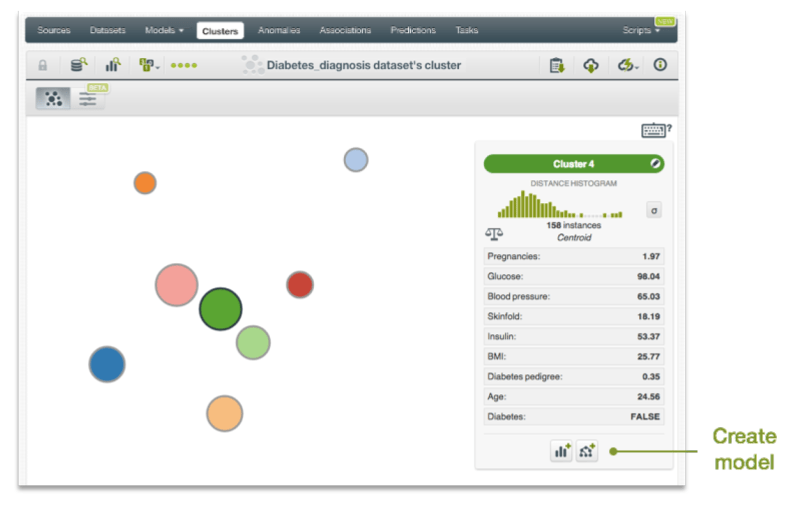
In fact, there is already a one-click way to grow a tree based on a cluster just this way. When viewing a cluster in the BigML dashboard, if you shift click on a particular cluster, below on the right you can click to create a model (a single tree) from this cluster. This will give you the importance of each input field, but only to this cluster. But until now, there was no easy way to see the overall importance of each field considering all the clusters.
Global importance is here!
This new BigML script creates not just one, but an ensemble of trees designed to find the importance of your input fields. With just a few clicks, you will know which fields contribute to how your clusters were decided. And because the script uses an ensemble, you can be more confident that these fields really are the ones you want.
You can import this script directly from our gallery here. Now you are ready to analyze your cluster! Pick any of your clusters from the dropdown menu. Whether it was a fast one-click cluster, or you spent a long time carefully tailoring your cluster options, this script will be able to tell which input fields were the important ones. Once you’ve got your cluster, click “Execute” and let BigML do its thing. When complete, the output is importance-list, a map of input field id, field name and importance, ordered from most to least important.
Cluster Classification in more detail
This script is written in WhizzML, BigML’s new domain-specific language, WhizzML. If you have a complicated task to do, just a few lines of WhizzML can replace the repetitive clicking needed to massage data in the dashboard. The cluster classification script takes a cluster ID and uses WhizzML to:
- Create an extension of the cluster’s source dataset, adding a new field ‘cluster’
- Create an ensemble from those resources.
- Put it all together to report each field’s importance.
This only takes a few steps because the script exploits the features of two BigML resources: the batchcentroid and the ensemble. Many BigML resources automatically contain calculated information that would be too much to show in the dashboard. But with a little WhizzML we can reveal their secrets.
Here’s the function that creates the extension of the cluster’s source dataset:

It begins with define, which is how all WhizzML functions are defined. Here, a function label-by-cluster is defined to take as an input the cluster id cl-id. Next, a let expression assigns some variables to objects pulled out of that cluster. Here’s where BigML resources really shine. We ultimately want a dataset resource, and we could create the dataset we are after using Flatline to edit every row of the original dataset. But instead we will create a batchcentroid. Set the output_dataset parameter to true, and a batchcentroid resource automatically creates a dataset where each row is labeled by its cluster. But we want this dataset to have all the same fields as the original in addition to this new cluster field. So we set the parameter output_fields to the be the same fields as the original, and we’ve got exactly what we want!
Now that we have this extended dataset, we can figure out how important each field is in determining cluster membership by building an ensemble of trees with cluster membership as the objective. BigML automatically calculates the importance of each field in a model, we just have to know where to look to get those numbers.
Here’s the function that creates a map of field ids and their importance:

Just as before, define creates the function make-importance-map, which takes an ensemble id and a list of input field ids as inputs. In the let statement, we go into the ensemble and pull out a list of all the models it contains, then go into get model to pull out the list of field importances. Now we just have to put everything together. Without getting too lost in details, the helper functions list-to-map turns our lists into maps and merge-with combines all the maps by addition. One final map to divide by the number of models, and we have a map of field importance averaged over all the models of the ensemble.
That’s it in a nutshell! If you have ever spent a lot of time carefully setting cluster parameters, only to find you aren’t really sure why your clusters were chosen as they were, this is the script for you. It will tell you exactly which fields are important not just to a single cluster, but across all of them. More understanding is just a few clicks away.
