When people first see a demo of BigML, there is often a sense that it is magical. The surprise likely stems from the fact that this isn’t how people are accustomed to computers working; rather than acting like a calculator creating a fixed outcome, the process is able to generalize from patterns in the data and make seemingly sentient predictions.
However it is important to understand that predictive analytics is not magic, and although the algorithm is learning on a very basic level, it can only extract meaning from the data you give it. It does not have the wealth of intuition that a human has, whether that’s good or bad, and subsequently the success of the algorithm can often hinge on how you engineer the input features.
Let’s consider a very simple learning task — please keep in mind that this is a contrived example to make explaining the problem of feature engineering clear, and does not necessarily represent an actual useful end result itself.
Assume you are working on a navigational system, and at some point in the system you would like a way to predict the principal direction of a highway knowing only its assigned number. For example, if a user wants to go north, and there are two nearby highways, Interstate 5 and Interstate 84, which should they take?
Now, you could use a list of known highways, but this would require you to regularly update the list as new highways are built, or removed. Instead, if there was a pattern relating principal direction to highway number, this might be a useful thing for you device to know.
So, let’s take a list of primary interstates in the US and let BigML train a model to predict the principal direction: East-West or North-South. The resulting tree looks like this:
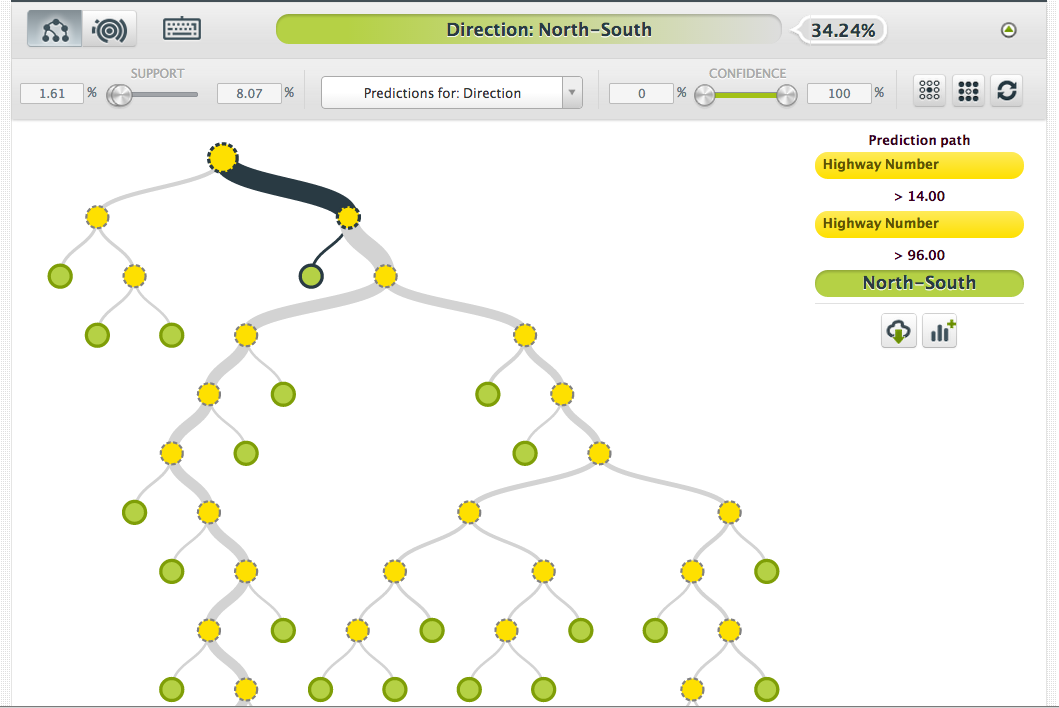
In the highlighted node, you can see that the learning algorithm has discovered that if the highway number is greater than 96, then the highway is principally North-South. And indeed, if we look at the dataset there are only two highways that match this pattern, 97 and 99 and they are both North-South and so this pattern is relevant.
However, as you navigate around the tree it becomes obvious that each split is simply creating bounds that eventually isolate a single highway or a small group of highways, at which point the prediction is less of a generalization and more of a truism:
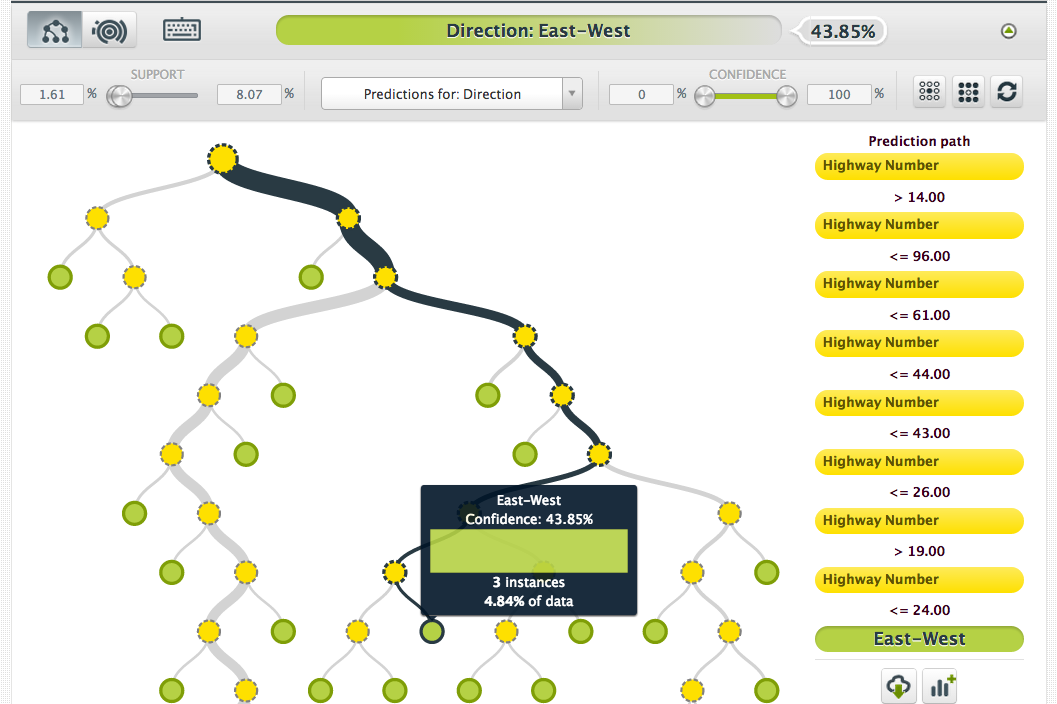
In other words, the model doesn’t seem to be generalizing in a meaningful way from the highway number to the principal direction.
Now if you are familiar with the US highway numbering system then you might know that there is significance in whether the highway number is even or odd. Lets re-engineer our dataset to include this property and see if the model changes. We can do this by selecting the “Add Fields to Dataset” option:
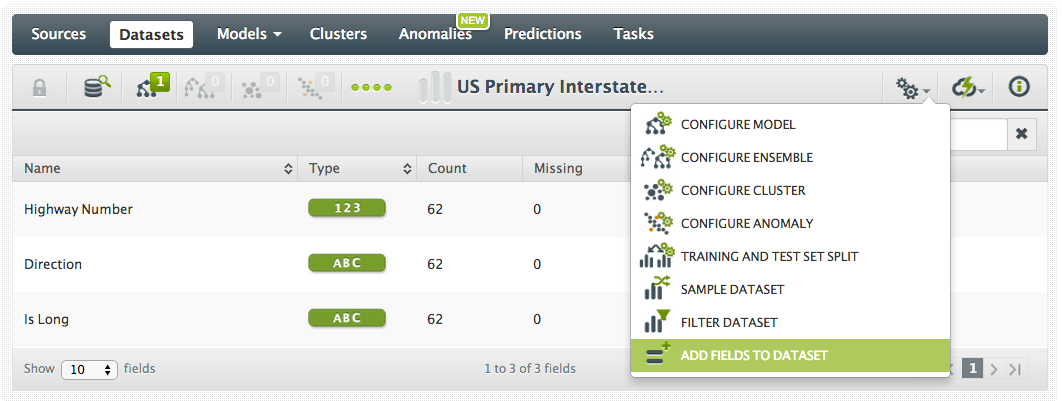
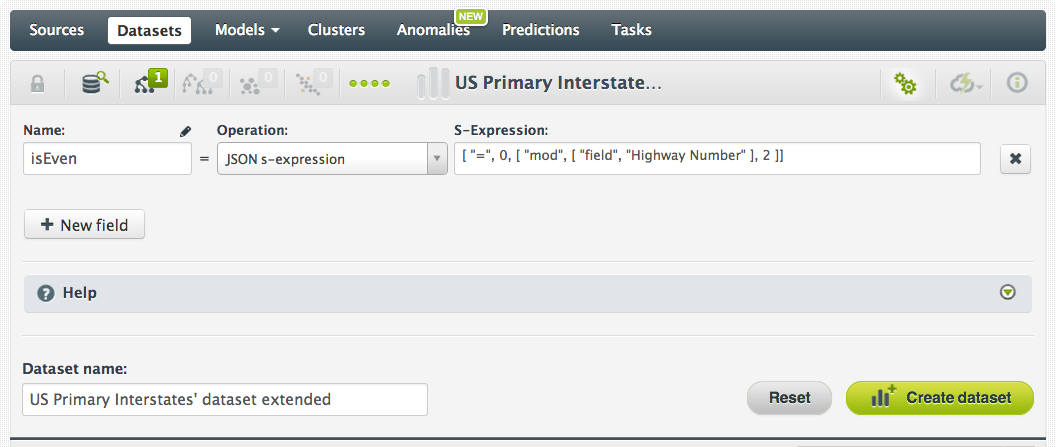
We’ll call the new field “isEven” and define it with the JSON s-expression:
[ "=", 0, [ "mod", [ "field", "Highway Number" ], 2 ]]
Reading from the inside brackets, we take the field named “Highway Number” and compute this value mod 2. If it equals 0, then this expression will return True meaning the highway number is an even integer, and False if odd:
Now we re-build the model including this new feature:
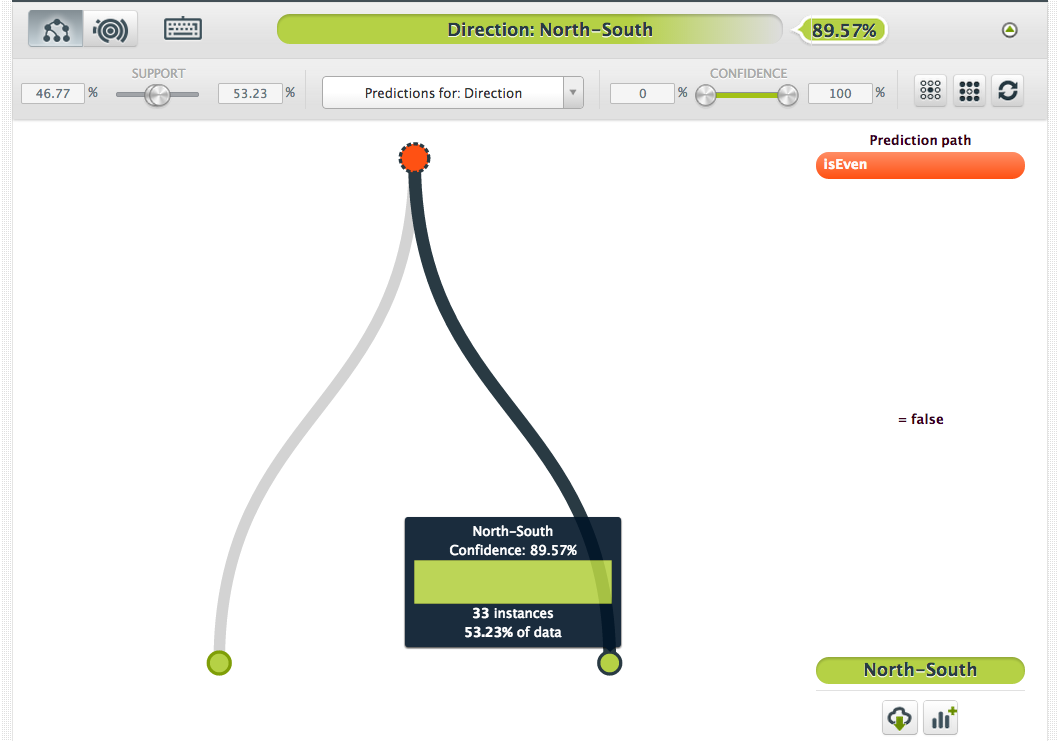
And now we get a very simple tree which generalizes to the following rules:
IF isEven = false THEN
direction = North-South
IF isEven != false THEN
direction = East-West
This is a much more useful generalization! But what is happening here? Why didn’t the machine learning algorithm find this pattern in the first tree?
Remember the first dataset: all we gave the algorithm to learn from was an integer. And the only thing the algorithm knows about integers is that they have a natural order. That’s it. And so, it tried to find a pattern relating the natural order of the integers to the principal highway direction.
As humans, we potentially know a *lot* more about integers: some are squares, some are prime, some are perfect, and some are even. In the second dataset, we added some of this additional information about integers, specifically the even-ness, to the algorithm. By engineering this feature, we gave the algorithm the extra information it needed to find the pattern. In other words:
1) The “Feature Engineering” was adding the even/odd property.
2) The “Machine Learning” was the discovery that the even/odd property determines the principal direction.
The insight here is that learning algorithm can only discover the patterns that we provide in the data, either intentionally or accidentally.
In this rather contrived example, it might seem circular. That is, we start with an insight that even/odd has meaning, add that property, and then discover that even/odd has meaning. However, it is important to remember that this is a very simple example. When working with real data you may have hundreds or thousands of features and the patterns will be much more nuanced.
In that real world case, the importance of feature engineering is to use domain specific knowledge and human insight to ensure that the data contains relevant indicators for the prediction task. And, in that case, the beauty of machine learning is that it discovers the relevant patterns and filters out the incorrect human insights.
If you would like to run this example in your own account, here is a little python script which reproduces all the steps in development mode (FREE):

2 comments