
September 3, 2014 3:37 pm
I recently came across a 1995 Newsweek article titled “Why the Web Won’t be Nirvana” in which author and astronomer Cliff Stoll posited the following:
“How about electronic publishing? Try reading a book on disc. At best, it’s an unpleasant chore: the myopic glow of a clunky computer replaces the friendly pages of a book. And you can’t tote that laptop to the beach. Yet Nicholas Negroponte, director of the MIT Media Lab, predicts that we’ll soon buy books and newspapers straight over the Internet. Uh, sure.”
Well, it turns out that Mr. Stoll was slightly off the mark (not to mention his bearish predictions on e-commerce and virtual communities). Electronic books have been a revelation, with the Kindle format being far and away the most popular. In fact, over 30% of books are now purchased and read electronically. And Kindle readers are diligent with providing reviews and ratings for the books that they consume (and of course the helpful prod at the end of each book doesn’t hurt).
So that got us thinking: are there hidden factors in a Kindle book’s data that are impacting its rating? Luckily, import.io makes it easy to grab data for analysis, and we did exactly that: pulling down over 58,000 kindle reviews which we could quickly import into BigML for more detailed analysis.
My premise going into the analysis was that author and words in the book’s description, along with length of book, would have the greatest impact on the number of stars that a book receives in its rating. Let’s see what I found out after putting this premise (and the data) to the machine learning test via BigML…
We uploaded over 58,000 Kindle reviews, capturing URL, title, author, price, save (whether or not the book was saved), pages, text description, size, publisher, language, text-to-speech enabled (y/n), x-ray enabled (y/n), lending enabled (y/n), number of reviews and stars (the rating).
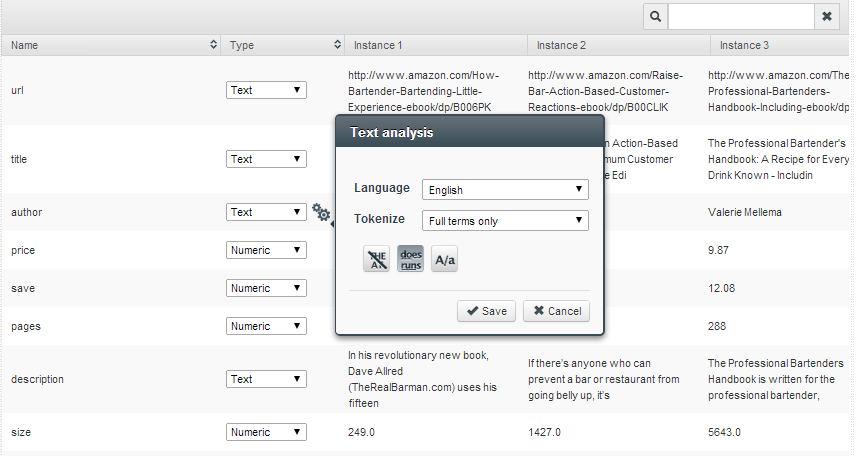
This data source includes both text, numeric and categorical fields. To optimize the text processing for authors, I selected “Full Terms only” as I don’t think that first names would have any bearing on the results.
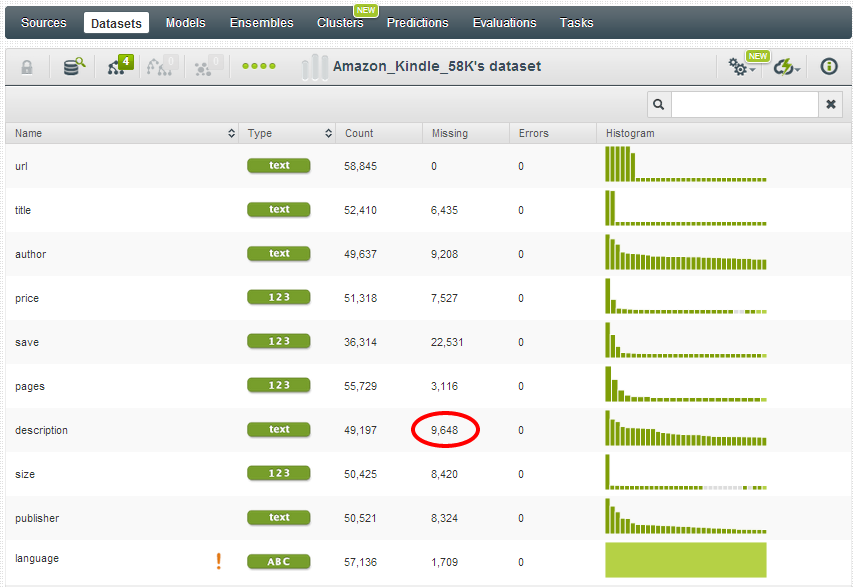
I then created a dataset with all of the fields, and from this view, I can see that several of the key fields have some missing values:
Since I am most interested in seeing how the impact of the book descriptions impact the model, I decide to filter my dataset so that only the instances that contain descriptions will be included. BigML makes it easy to do this by simply selecting “filter dataset”:
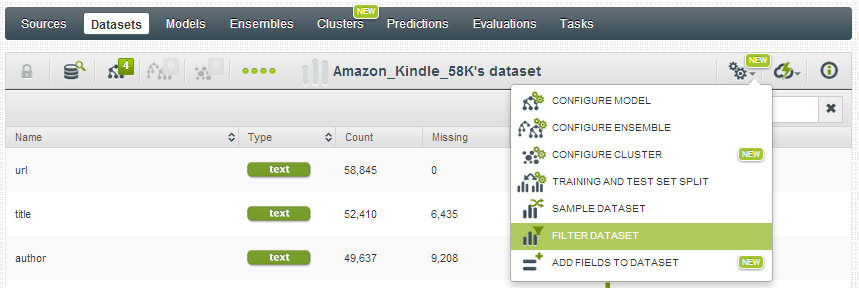
and from there I can choose which fields to filter, and how I’d like them to be filtered. In this case I selected “if value isn’t missing” so that the filtered dataset will only include instances where those fields have complete values:

And just like that, I now have a new dataset with roughly 50,000 rows of data called “Amazon Kindle – all descriptions” (you can clone this dataset here). I then take a quick look at the tag cloud for description, which is always interesting:
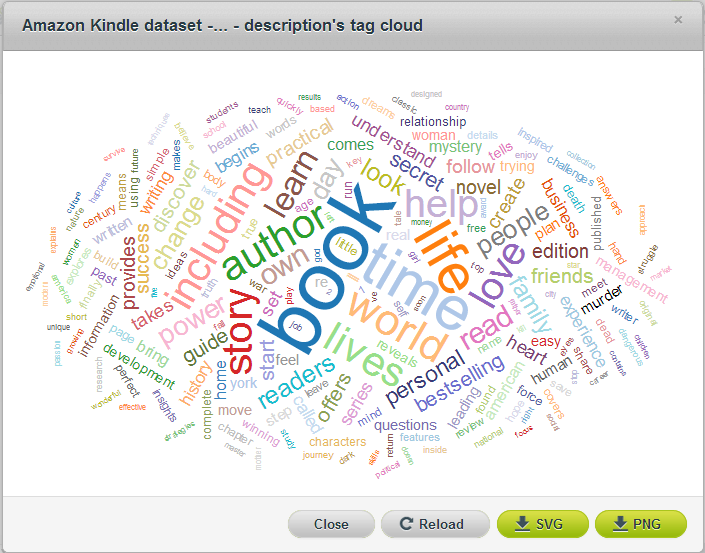
In the above image we see generic book-oriented terms like “book,” “author,” “story” and the like coming up most frequently – but we also see terms like “American,” “secret,” and “relationship” which may end up influencing ratings.
My typical approach is to build a model and see if there are any interesting patterns or findings. If there are, I’ll then go back and do a training/test split on my dataset so I can evaluate the strength of said model. For my model, I tried various iterations of the data (this is where BigML’s subscriptions are really handy!). I’ll spare you the gory details of my iterations, but for the final model I used the following fields: price, pages, description, lending, and number of reviews. You can clone the model into your own dashboard here.
What we immediately see in looking at the tree is a big split at the top, based on description, with the key word being “god”. By hovering over the nodes immediately following the root node, we see that any book that contains the description “god” has a likely review of 4.46 stars:
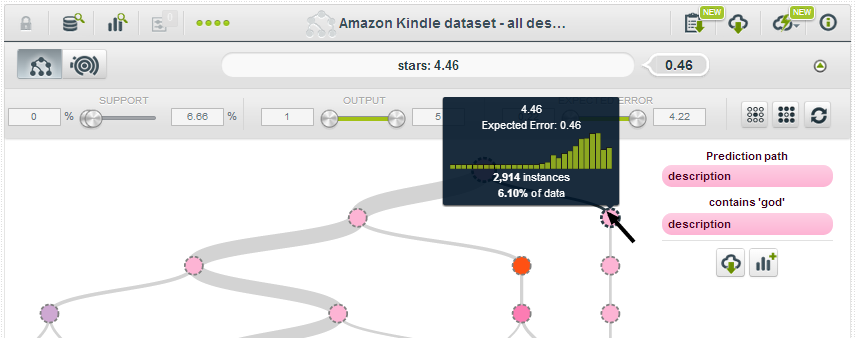
while those without “god” in the description have a rating of 4.27:
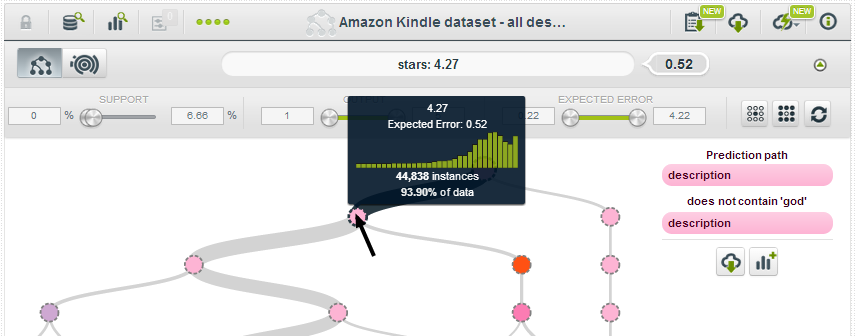
Going back to the whole tree, I selected the “Frequent Interesting Patterns” option in order to quickly see which patterns in the model are most relevant, and in the picture below we see six branches with confident, frequent predictions:
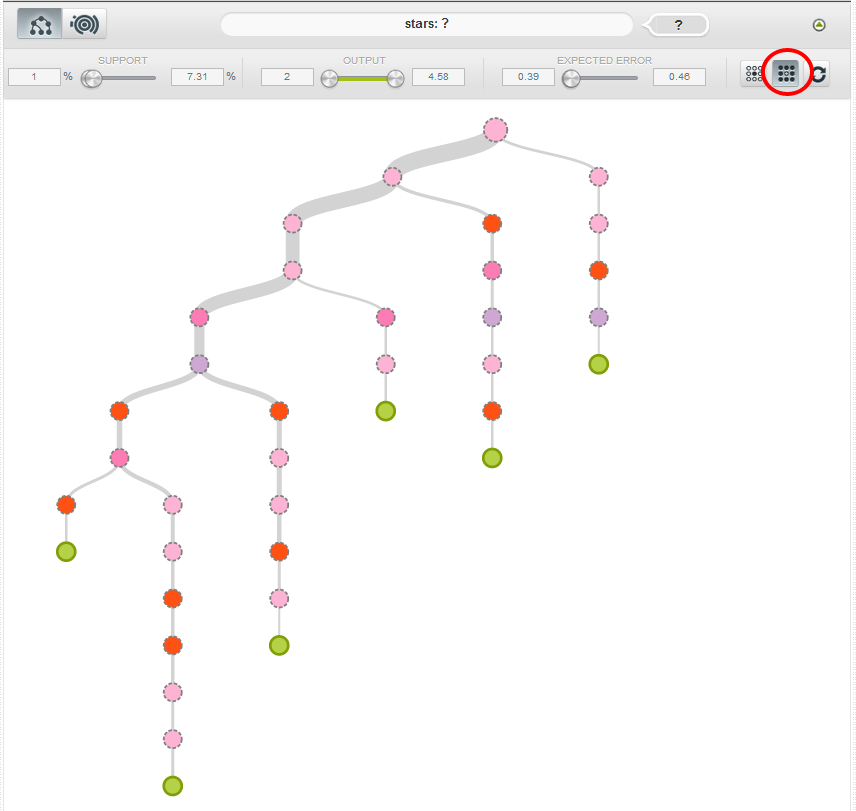
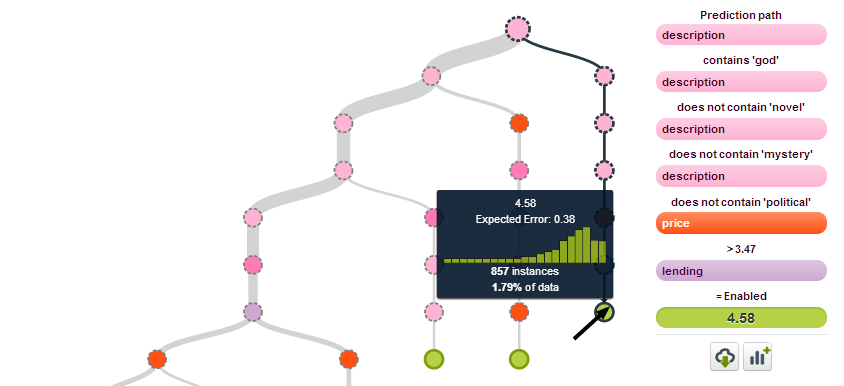
The highest predicted value is on the far right (zoomed below), where we predict 4.57 stars for a book that contains “god” in the description (but not “novel” or “mystery”), costs more than $3.45 and has lending enabled.
Conversely, the prediction with the lowest rating does not contain “god,” “practical,” “novel” or several other terms, is over 377 pages, cannot be loaned, and costs between $8.42 and $11.53:
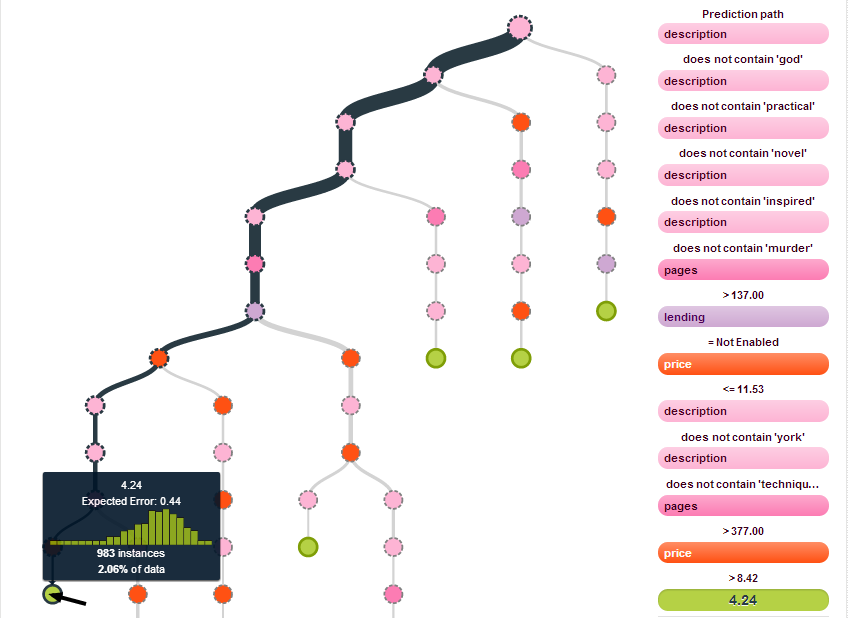
Looking through the rest of the tree, you can find other interesting splits on terms like “inspired” and “practical” as well as the number of pages that a book contains.
Evaluating your model is an important step as data most certainly can lie (or mislead), so it is critical to test your model to see how strong it truly is. BigML makes this easy: with a single step I can create a training/test split (80/20), which will enable me to build a model with the same parameters from the training set, and then evaluate that against the 20% hold-out set. (You can read more about BigML’s approach to evaluations here).
The results are as follows:
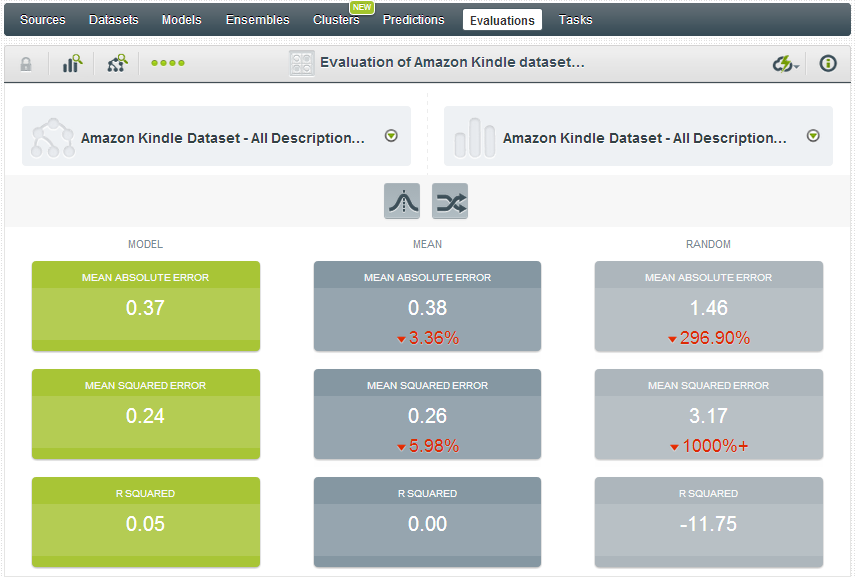
You can see that we have some lift over mean-based or random-based decisioning, albeit somewhat moderate. Just for kicks, I decided to see how a 100-model Ensemble would perform, and as you’ll see below we have improvement across the board:
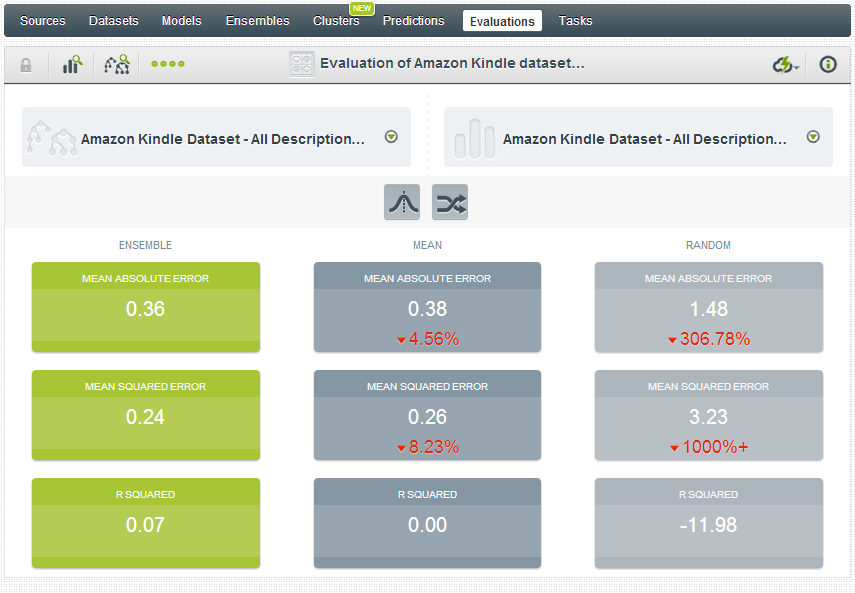
This was largely a fun exercise, but it demonstrates that machine learning and decision trees can be informative beyond the predictive models that they create. By simply mousing through the decision tree I was able to uncover a variety of insights on what datapoints lend themselves to positive or less positive Kindle book reviews. From a practical standpoint, a publisher could build a similar model and factor it into its decision-making before green-lighting a book.
Of course my other takeaway is that if I want to write a highly-rated Kindle title on Amazon, it’s going to be have something to do with God and inspiration.
PS – in case you didn’t catch the links in the post above, you can view and clone the original dataset, filtered dataset and model through BigML’s public gallery.
Posted by andrewshikiar
Categories: Data, Model of the Week, Tutorial
Tags: Amazon, evaluations, import.io, Kindle, predictive models, use case
Mobile Site | Full Site
Get a free blog at WordPress.com Theme: WordPress Mobile Edition by Alex King.
Reblogged this on HadoopEssentials.
By Nitin on September 4, 2014 at 4:30 am