As a novice in this machine learning field, I managed to make a lot of mistakes. But I was fortunate to have knowledgable and patient colleagues who guided me on the straight and narrow path to predictive success (like Charlie Parker, who co-authored this post). Here are 3 machine learning mistakes I managed to make more than once. I hope it’ll help you to recognize and understand them when you happen to encounter them using BigML.
1-node model
There’s a sense of anticipation as you watch a predictive model being built, layer by layer in BigML’s web interface. But for some of my datasets, it would stop at the root node, leaving me with a perfectly useless 1-node decision tree. I remember filing it as a bug the first time it happened!
It turned out that I had used a skewed dataset. The classes for my objective field were not balanced in the training set. If for instance 99% of my training set would have “TRUE” as class for it’s objective feature, the model would simply predict “TRUE” in all cases and be 99% accurate. It’s a mistake that is simple to remedy, if you have enough data: Simply throw out some of the data from the dominant class. Be careful not to throw out too much, though (you don’t want to throw away useful data) and be sure to pick the points you throw away at random, otherwise you might introduce some bias.
How much should you throw away? It’s a bit of a guessing game, but sometimes the relative importance of the two classes can provide an insight: Say it’s 10 times more important to you to get the “FALSE” examples right than the “TRUE” examples. A good place to start might be to throw as much data away as you need to to make the “FALSE” class 10 times more likely than it was in the original dataset. So if the dataset is 1% “FALSE”, throw out “TRUE” examples until it is 10% “FALSE”.
Can’t afford to throw away data? Another similar strategy is just to replicate the “FALSE” datapoints until you have the desired number (in the example above the strategy would be to replicate each point 10 times). This is another way of telling the modeling process that the “FALSE” points are more important than the “TRUE” points, and they can’t just be ignored without a significant performance decrease.
One Feature Spoils the Party
I remember working really hard on a dataset that contains property data and house prices in Manhattan. Every instance had both the actual sales price and an indexed price. This way I could compare the sales prices over time. I was excited when I finally uploaded the dataset and was quick to push the 1-click model option. The resulting tree was disappointing, to say the least. It predicted the indexed price but mainly had ‘price’ as feature in the tree. After all, knowing the price is a perfect indicator of the indexed price! In my enthusiasm to create a model, I had forgotten to exclude ‘price’ and ended up with (again) a perfectly true but useless model.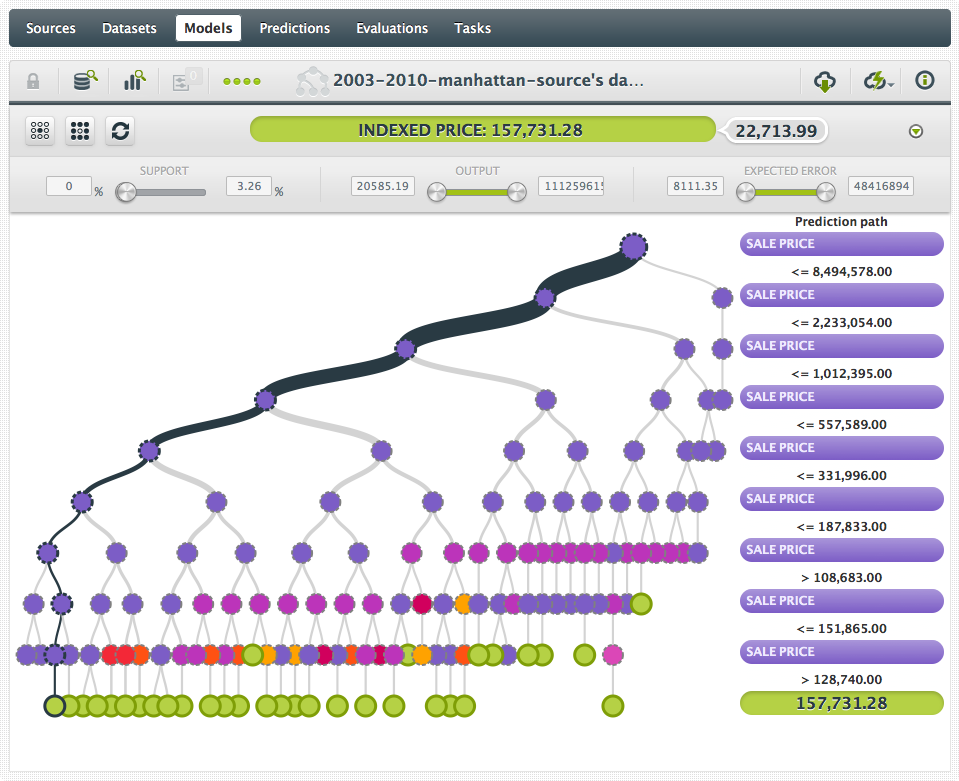
This happened to me more than once, where one feature would be a good or even perfect predictor for the objective feature. Another good example is datasets that have both the total value for the objective, and some kind of average value as well; they’re usually not perfect proxies for each other, but often you can predict one from the other with pretty high accuracy. Usually, that’s not helpful as you’re not going to know either one ahead of time, so a predictor for one from the other is useless.
The cure is again quite simple. If you find such a relationship in your dataset, simply deselect the feature that is bothering you and run your analysis again.
Too Many Classes
While the previous mistakes are quite obvious and render useless models, the last mistake took me longer to appreciate. Quite proudly I would share a model with one of my colleagues only to hear the experts say ‘too big’ or ‘too wide’ (always in a constructive and respectful tone, of course!). How can a tree be too big or too wide?
One particular feature that occurs a lot in US datasets is for instance ‘State’. Since there are 50 US states, a node that splits on ‘State’ could split into 50 different branches. If that happens more than once in a tree, you can get a very wide tree indeed. A similar feature would be ‘country’ if you use international data. If your tree splits on such a feature with a lot of classes, the data is divided after that split into a lot of small buckets and the support for each following decision is getting lower and lower. Once the data gets small (at the lower leaves of the tree), splitting the data 50 ways just isn’t useful anymore. Said another way, if you’ve got 50 categories, you need a whole lot of data to fill them up.
BigML limits the number of categories you can use for a feature to 300. If the feature has more categories than that it is considered a text item and is automatically deselected from the analysis. Even if your feature has more than 35 categories, it is automatically deselected but still labeled categorical. This allows you to override this deselection by manually selecting this feature to include it in your analysis.
One way of improving the performance of trees with features that have many classes is to bundle classes. For instance, in stead of ‘state’ you can add a feature called ‘region’ to limit the number of classes. Likewise for ‘country’ you can add ‘continent’. This can go all sorts of ways. Perhaps “coastal” and “non-coastal” or “primarily urban” and “primarily rural”. In machine learning speak, this is called ‘feature engineering’ and it is a crucial technique to improve the performance of your model. In any case, a five-category feature, bundled in a useful way, is almost always more useful than a raw 50-category feature. But if you do think ‘State’ is of high importance and you have enough data per state, you can consider splitting the training set per state. This way you’ll create a predictive model per state and be able to find differences per state in the predicted results.
Finally
You learn from your mistakes. The first step is to recognize them and know how to remedy them. Even when using a tool like BigML, it is quite possible to make mistakes like these. I am fortunate to have my machine learning colleagues around to help me. If you run into similar issues and you are left clueless, make sure to let us know. We are not in the business of machine learning consultancy or training but we do want you to be successful in applying BigML’s machine learning platform.

Hi, great article and common hurdles in machine learning 🙂 I would add to your comment on your skewed data set issue and your suggestion to remove data from one of your classes. In general terms it is almost always better to have more data in machine learning challenges. An alternative solution to your issue is to use an alternative measure of success (you rightly point out that accuracy is not a good measure in this skewed case) using something like the F1 measure which is a ratio that makes use of recall and precision will negate the issues seen with the accuracy measure.
Thanks Matt for your remarks. BigML indeed will compute an F1 measure when you create an evaluation (as well as recall and precision).