The Quantified Self movement is entering the realm of Big Data with the ability to access the mountains of data collected by personal devices which monitor us continuously (hopefully with our consent). One example is iTunes which surpassed 200 million accounts in March of 2011. iTunes records every play, every skip, and every song you add to your digital library. If you are an active iTunes user, this can quickly become a large amount of data and useful insights can be hard to discover. Consider that as far back as 2003, entire start-up companies emerged to try and leverage this data: MusicStrands (where a few of us at BigML worked before), Musicmobs, Last.fm, etc. However in this post we will show you how trivial it now is to gain insights from iTunes data using the powerful machine learning capabilities of BigML.
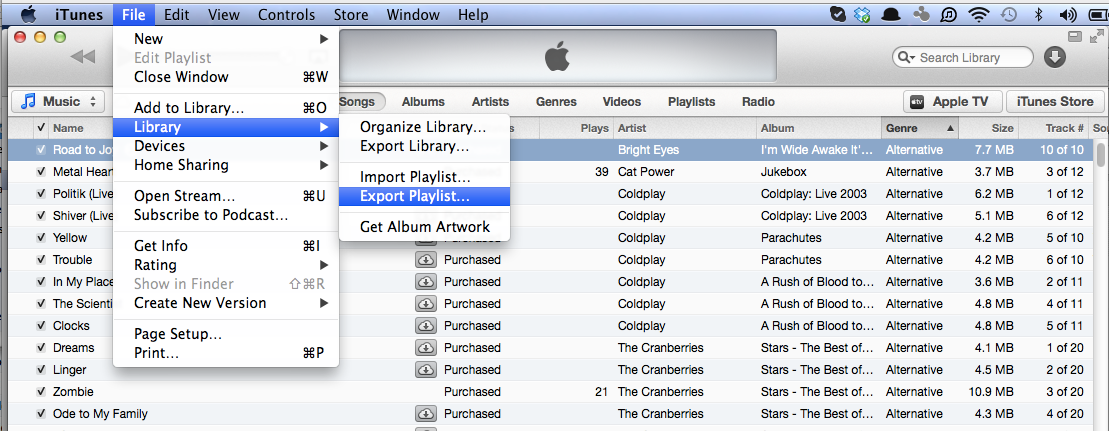
iTunes has a great user interface with hundreds of great features but probably the favorite one for data nerds is that you can right click on one of the tabs of your library (Music, Movies, TV Shows, etc) and export all the data that iTunes collects to a file. You can even select among several file formats.
The default format generates a plain text, TSV (tab-separated value) file that is the perfect format to be automatically processed by BigML.
So just save the file “Music.txt” in a convenient place for you. Then drag and drop the new file into your BigML dashboard to create a new Source. In a few seconds, you will see a preview of the data in BigML.
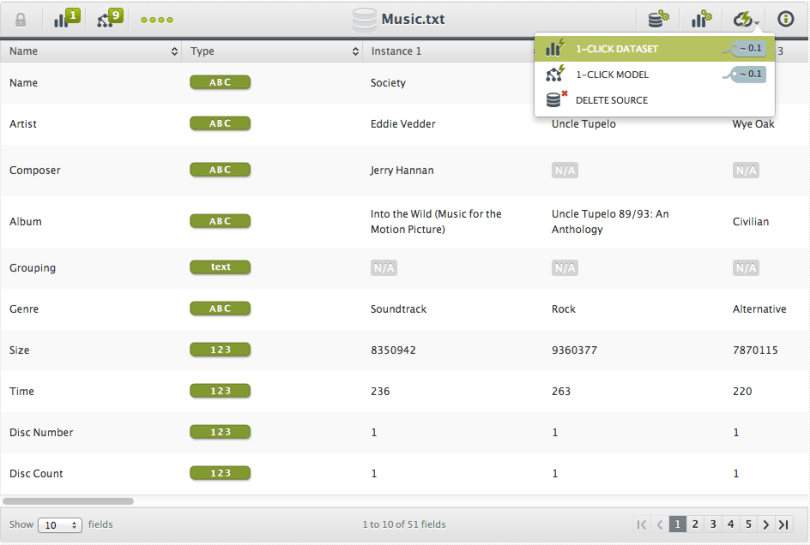
You can use the 1-click dataset menu option to create a new Dataset. In a few seconds, you’ll start seeing some fancy histograms, one for each of the fields in your music library.
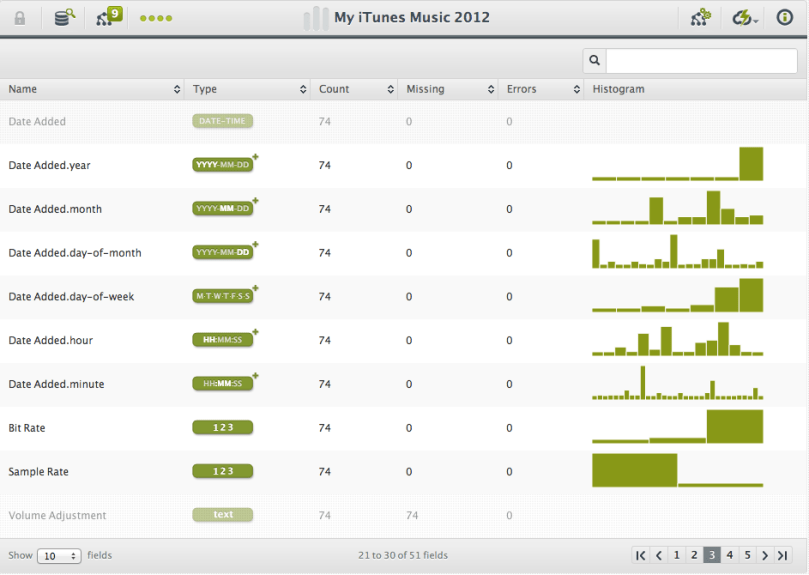
Then your own personal discovery starts. You will be able to see from the histograms alone what month of the year you added more music to your library, what genres are more dominant, whether you prefer new music or old, etc.
But there is deeper insights to be gained. You can start creating Models selecting or deselecting any of the fields in your dataset to see how they correlate and predict other fields. For example, you can predict the number of plays based on the genre, the date that you added a song, the year of a song, etc.

A surprising insight about my own iTunes data: the songs I play more often are the songs that I buy between Tuesdays and Thursdays, even though I buy many more songs on Saturdays and Sundays. Upon further investigation, I found that most of them were songs from a soundtrack. As it turns out, I usually watch new movies on Mondays as soon as they are available on iTunes, and if a song from the movie makes a good impression and I still remember it two days later, then I buy it and play it a lot.
Despite debate about how Apple is becoming more closed, it would be great if many other applications or services allowed you to get access to your own data as easy as iTunes does. Because once you have access BigML makes discovery easy.
Happy Predictive Modeling in 2013!!!
Update (January 5, 2013)
Some BigML users have told us that the export feature has slightly been changed in iTunes 11.0.1. It is now under File >> Library >> Export Playlist… One more thing, if you export your complete library, make sure that you have enough local songs. Otherwise, if most of your songs are still in iCloud, BigML might get confused with the correct number of fields in the header of the file generated by iTunes and you might need to delete the last field of the header to make it work (i.e., Location).

I tried this with my music.txt from itunes, but couldn’t find anything interesting in the model. So don’t know what i will listen to in 2013 …
What input fields did you use for your model? What objective field did you select?