Today marks the completion of a decade since a small group of Machine Learning and Software Engineering experts founded BigML back in 2011 with the audacious mission to make Machine Learning easy and beautiful for everyone. So we can’t help but proudly reminisce about a decade of hard work in building our platform while helping deliver a multitude of customer projects. As we witnessed our vision gradually turn into reality what we’re left with is a decade of valuable lessons in Machine Learning platform evolution and industry adoption.
As they say, time is the best teacher and patience is the best lesson. If we are to set our controls to January 2011 and travel back in time to remember the state of Machine Learning adoption in the business world a decade ago we can quickly share with you the following memories:
- First off, none of the players in today’s Machine Learning software category existed back then. That means only earlier versions of a few open-source libraries (i.e., Weka, scikit-learn, Mahout) were around. They all required users to download and install packages on their computers to analyze smaller static datasets mainly for research purposes. Only Google had a small project called Google Prediction API, but it was deprecated a few years later before any meaningful commercialization.
- Machine Learning academics had not yet started their mass migration towards Silicon Valley employers and were primarily concerned about their research, which they thought only appealed to their academic peers. For instance, Professor Pedro Dominguez of the University of Washington didn’t yet have Twitter account. In 2013, when BigML published the guest blog post series, Everything You Wanted to Know About Machine Learning, But Were Too Afraid To Ask, it suddenly topped Hacker News. Capitalizing on the new business interest in Machine Learning in the 2010s, Professor Dominguez went on to publish his much-praised book, The Master Algorithm, effectively simplifying the core concepts of Machine Learning for a much broader audience that was hungry for a better understanding of the potential impact of the technology in their respective industries.
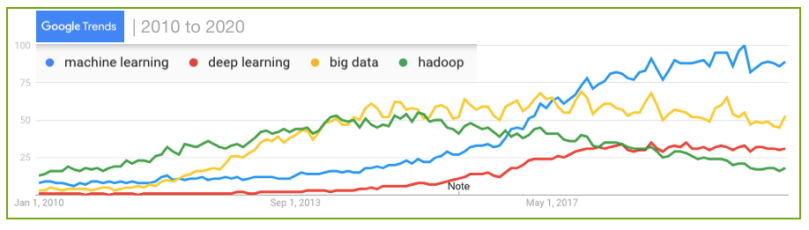
- Back then, VCs weren’t even curious about this thing called “Machine Learning.” Many didn’t know exactly how it contrasted with Artificial Intelligence or Deep Learning. They strongly believed that the recently open-sourced Hadoop and MapReduce were going to solve all the problems of the world. By the middle of the decade “Big Data” was becoming all the rage on the back of the attention the open-sourced Hadoop library was getting from enterprise software developers and architects as fueled by ungodly amounts of VC dollars and a continuum of conferences. As seen above, it’s not until 2016 and 2017 when Machine Learning became more popular, which meant pure-play ML companies had to paddle through the tricky “Big Data” rapids and its noisy and often misleading ripple effects. In the end, as expectations and valuations came down to earth, even the largest VC-backed open-core companies had to consolidate to stay alive.
- The number of attendees to NIPS (now NeurIPs) hadn’t yet surpassed even a measly 1000. The mass hiring of successful ML academics by Big Tech resulted in that same list of companies and their joint venture organizations dominating the top published research, in turn, causing controversy.
- After BigML’s beta version was launched in early 2012, the majority of the people that signed up were the Machine Learning specialists drawn to the elaborate visualizations the BigML Dashboard brought to the market. However, over time, we started observing a different type of end-user like developers looking to build smart applications without having to go back to school for a Master’s Degree. Most came for the beautiful visualizations but stayed for the comprehensive REST API and accompanying developer tools that we’ve been offering as an “API-first” company since inception.
- Google’s “mysterious X lab” hadn’t yet publicly shared the results of their headline-grabbing search for cat videos based on their “Artificial Brain.” In typical popular press style, the history of Deep Learning and the fact that it was based on mid-20th century concepts was not given much mention when the news came out. To this day, this unabashed pursuit of “Shiny Objects” by popular press persists diverting precious attention from what would be real-world business applications however unsexy they may be.

In summary, at the beginning of the 2010s, the main motivations behind BigML founders’ charge to create a brand new Machine Learning platform from scratch were threefold:
- There were simply no well-engineered frameworks to develop predictive applications, e.g., Weka crashed when it was fed datasets larger than 1GB.
- The lack of automation was a glaring need to slow down development efforts. There were no well-defined APIs to automate sophisticated Machine Learning workflows.
- The existing toolset was not only incomplete but also overly complex as they were designed by scientists for scientists. This was perhaps fine for research purposes but sorely lacking in an enterprise setting, where aspects such as repeatability, traceability, and scalability were paramount.
How times change! Fast Forward to the Present Day…
Enough nostalgia, let’s change tunes and briefly touch on how the world of enterprise Machine Learning today contrasts with the previous decade.
The Good
Unlike the early 2010s, today, the awareness of the potential impact of Machine Learning in the business context has leaped to much higher levels. Gone are the days when we had to define Machine Learning while being greeted with blank stares from business prospects. By now, almost every industry has some positive examples of data-driven predictive applications experts can point at even if groundbreaking projects are still relatively few and far in between as compared to the technology’s full potential.
The Not So Good
The total cost of ownership of production deployed applications still leaves room for improvement from a financial perspective. We expect that the number of smart applications and their underlying predictive workflows will multiply calling into question the long-term viability of the high-touch, siloed processes that support existing implementations if we are to target massive expansion involving many more automated tasks. Unfortunately, the AI-hype machine fueled by popular press keeps churning out articles that incorrectly extrapolate research achievements but the tide is starting to turn as a more down-to-earth perspective more apt for the enterprise audience is finally starting to receive some oxygen.
The Potentially Ugly
The K-shaped recovery is an often discussed topic in these pandemic-stricken days thanks to the unequal rate of recovery between sectors and even between companies within sectors. While those at the top keep enjoying unprecedented access to capital markets in the form of new debt issuance or stock market offerings many other companies and sectors are starving at the edge of insolvency with highly doubtful futures in the absence of massive central bank and government stimulus.
Unfortunately, we expect a continuation of this trend in the near future among companies that are in the midst of their digital transformation vs. those that have their data and analytics houses already in good order. The market share shift from the former to the latter is likely to be of epic proportions in the following years as the world economies strive to get back on track with their pre-pandemic growth trajectories. This contrast can be partially explained by the compounding nature of data-driven innovations.
The Silver Lining
As long as they are willing to make a serious go at it, nimble startups and mid-market companies now stand a much better chance to dominate their niches thanks to predictive solutions built on top of more mature Machine Learning platforms like BigML readily available to them at a fraction of the cost of a single Data Scientist.
In the newly accelerating digitization wave and against the backdrop of antitrust proceedings that may slow down Big Tech’s relentless march to digitize and rule all markets, new billion-dollar opportunities may be there for the taking for new players that can reach their own version of the critical 88 mph innovation threshold warp speed to transform themselves into formidable regional or even global competitors by the end of 2020s.
To conclude this quick tour, we’d like to thank our 138,000+ users for making BigML part of their Machine Learning journey so far. We’re looking forward to serving you and many more to join the ride for another decade!
