As pointed in this Kdnuggets article, it’s often the case that we only have a few examples of the thing that we want to predict in our data. The use cases are countless: only a small part of our website visitors purchase eventually, only a few of our transactions are fraudulent, etc. This is a real problem when using Machine Learning. That’s because the algorithms usually need many examples of each class to extract the general rules in your data, and the instances in minority classes can be discarded as noise, causing some useful rules to never be found.

The Kdnuggets article explained several techniques that can be used to address this problem. Almost all those techniques rely on resampling the data so that all the possible outcomes (or classes) are uniformly represented. However, the last suggested method takes a different approach: adapting the algorithm to the data by designing a function, which penalizes the more abundant classes and favors the less populated ones using a per-instance cost function.
In BigML, we already have solutions that can be applied out-of-the-box to balance your unbalanced datasets thus improving your classification models. The model configuration panel offers different options for this purpose:
- a balance objective option, that will weight the instances according to the inverse of the frequency of their class.
- an objective weight option, where you can associate the weight of your choice to each particular class in your objective field (the one to be predicted when classifying)
- a weight field option, where you can use the contents of any field in your dataset to define the weight of each particular instance.
By using any of these options, you are telling the model how to compensate for the lack of instances in each class.
The first two options offer a way of increasing the importance that the model gives to the instances in the minority class in a uniform way. However, the article in Kdnuggets goes one step further and introduces the technique of using a cost function to also penalize the instances that lead to bad predictions. This means that we need to tell our model when it’s not performing well, either because it’s not finding the less common classes or because it’s failing in the prediction of any of its results. For starters, we can add to our dataset a new field containing the quantity to be used in penalizing (or increasing the importance of) each row according to our cost function. We can then check if the model results improve as we introduce this field as the weight field.
Fortunately, we have WhizzML, BigML’s domain-specific language that allows the creation of customized Machine Learning solutions. And it’s perfect for this task. So we’ll apply it to build a model that depends on a cost function and check whether it performed better than the models built from raw (or automatically balanced) data.
Scripting automatic balancing
The way to prove that balancing our instances is improving our model is evaluating its results and comparing them to the ones you’d obtain from a model built on the original data. Therefore, we’ll start by splitting our original data into two datasets and keeping one of them to test the different models we’re going to compare. The 80% of data will then form a training dataset that will be used to build the models and we will hold out the remaining 20% to evaluate their performance. Doing this in WhizzML is a one-liner.

The create-dataset-split procedure in WhizzML takes a dataset ID, a sample rate and a seed, which is simply a string value of our choice that will be used to randomly select the instances that go into the test dataset. Having the same seed will ensure that, even if the selection of instances is random, it will be deterministic and the same instances will be used every time you run the code.
Once we have our separate training data, we can build a simple decision tree from it.

The model-options argument is a map that can contain any configuration option we want to set when we create the model. The first attempt creates the model by using default settings, so model-options is just an empty map. This gives us the baseline for the behavior of models with raw unbalanced data.
Then we evaluate how our models perform using the test dataset. This is very easy too:

The model-id variable contains the ID of any model we evaluate.
We’re interested in predicting a concrete class (when evaluating, we name this the positive class). If the dataset is unbalanced, the positive class is usually the minority class. In this case, the default model tends to perform poorly. As a first step to improve our basic model, we try to create another model that uses automatic balancing of instances. This method assigns a weight to each instance that is inversely proportional to the frequency of the class it belongs to. This assigns a constant higher weight to all instances of the minority class and a lower one for instances in the abundant classes. In WhizzML, you can easily activate this automatic balancing with model-options {"balance_objective" true}. Usually, for unbalanced data, this second model will give better evaluations than the unbalanced one. However, if the performance of this second model is still not good enough for our purpose we can further fine tune the contribution of each instance to the model as described before. Let’s see how.
Scripting a cost function as a weight per instance
The idea here is that we want to improve our model’s performance, so besides assigning a higher weight to the instances of the minority class uniformly, we would like to be able to weight higher those instances that contribute to the model being correct when predicting. How can we do that?
Surely, the only way to assert a model’s correctness is evaluating it, so we need to evaluate our models again, but in this case, we don’t need the average measures, like accuracy, precision, etc. Instead we need to compare one by one the real value of the objective field against the value predicted by the model for each instance. Therefore, we will not create an evaluation, but a batch prediction.

A batch prediction receives a model ID and a test dataset ID and runs all the instances of the test dataset through the model. The predictions can be stored together with the original test data in a new dataset, and also the confidence associated with them. Thus, we’ll be able to compare the value in the original objective field column with the one in the predicted column. Instances whose values match should then receive more weight than instances that don’t.
At this stage, we’re ready to create a cost function that ensures:
- instances of the minority class weigh in more than the rest
- instances that are incorrectly predicted are penalized with a higher cost (so a lower weight in the model)
There’s room for imagination to create such a function. Sometimes your predictions will be right when they predict the positive class (TP = true positives) and sometimes otherwise (TN = true negatives). There are two possibilities for the predictions to be wrong: instances that are predicted to be of the positive class and are not (FP = false positives), and instances of the positive class whose prediction fails (FN = false negatives). Each of these classes, TP, TN, FP, FN have an associated cost-benefit.
Let’s assume your instance belongs to the class of interest and the model predicts it well. This is a TP and we should add weight to the instance. On the contrary, if it isn’t predicted correctly we should diminish its influence, which means for a FN the weight should be lower. The same happens with TN and FN. Following this approach, we come up with a different formula for each of the TP, TN, FP, FN outcomes. To simplify, we set such a weight as:
- when the prediction is correct, its confidence is multiplied by the inverse frequency of the class (total number of instances in the dataset over the number of instances of the class).
- when the prediction isn’t correct, the inverse of the confidence is multiplied by the frequency of the class.
If we create a dataset with a new column that has that weight, we can use the weight_field option when creating the model. Then, each instance is weighed differently during the model construction. Hopefully, this will improve our model. So let’s see if that’s indeed the case.
We start with the dataset obtained from our batch prediction, which contains the real objective value as well as the predicted value and confidence. We create a new dataset by adding a weight field, and that’s exactly what the following command does:

Using the new_fields attribute we define the name of our new column and its contents. The weight value should contain an expression that describes our weight function. To achieve this, we will use Flatline, BigML’s on-platform feature engineering language. The dataset we use is the batch prediction dataset, so it gets two additional columns: __prediction__ and __confidence__.

We won’t discuss here the details of how to build this expression, but you can see that in each row we compare the value of the objective field (f {{objective-id}}) to the predicted value (f \"__prediction__\") and use the confidence of the prediction (f \"__confidence__\"), the total number of instances {{total}} and the instances in the objective field class {{class-inst}} to compute the weight.
Now we have a strategy to weight our instances, but there’s an important detail that we need to keep in mind. We can’t use the same test dataset that we’ll use to evaluate the performance of our models to compute the weights. Otherwise, we’d be leaking information to our model, which it can use to cheat rather than generalizing well to our problem. To prevent this while avoiding splitting out our data again, we use another technique: cross validation.
Using k-fold cross validation predictions to define weights
In case you aren’t familiar with the k-fold cross validation technique, it splits your training dataset into k parts. One of them is held out for testing and you build a model with the remaining k-1 parts. You do so with one different part at a time, so you end up with k models and k evaluations and all of your data is used for training or testing in some of the evaluations.
Applying the same idea here, you split your dataset in k parts. Hold out one of the parts to be the test dataset and create a model with the rest. Then, use the model to create a batch prediction for the held out part. The weights that we want to assign to each instance in the hold out can be computed from the result of this batch prediction. The process is repeated with a different holdout each time, so every instance is weighted and the models that create the predictions are built on data completely independent from any particular test set.
In BigML we already offer scripts to do k-fold cross validation, so we don’t need to code the entire cross validation algorithm all over again. We just need to generate another copy by tweaking the existing script.
The change involves the creation of batch predictions instead of evaluations at the end of the process, so we simply change the code from this

to this
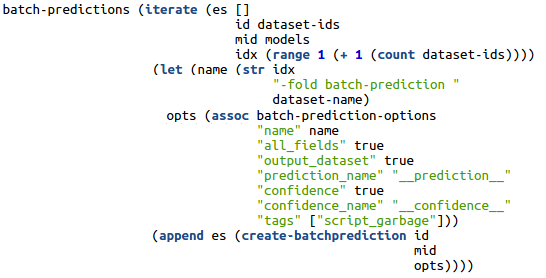
where the changes are mostly related to the fields we want to see in our newly created datasets and their names.
This small change in the script provides the datasets that we need to apply our weight computation function to. So, let’s sum up our work.
- We’ve split our original data into training and test datasets to compare the performance of different models.
- We’ve used the training data to create a model with the raw data and another one with our instances uniformly weighted to compensate the unbalanced situation.
- We have additionally divided the training data into k datasets and used the k-fold cross validation technique to generate predictions for all the instances therein. This process uses models built on data never used in the test procedure and also allows us to match the real value to the predicted result for each instance individually.
- With this information, we added a new column to our training dataset that contains a weight that is applied to each instance when building the model. This weight is based on the values of the frequency of the objective field class that the instance belongs to and also on the evaluation of its predictions by using the k-fold cross validation.
- The new weight column contained a different value per instance that is used when the weighted model was built.
- We finally used the test dataset to evaluate the three models: the default one, the automatically balanced one, and the one with a cost function guided weight field.
After testing with some unbalanced datasets, we achieved better performance using the weight field model than with either the raw or the automatically balanced ones. Even with our simple cost function, we’ve been able to positively guide our model and improve the predictions. Using WhizzML, we only needed to add a few lines of code to an already existing public script. Now it’s your time to give it a try and maybe customize the cost function to really make a difference in your objective functions’ gain vs. loss balance. You can access our script at https://gist.github.com/mmerce/cd87dc119bfbf6dcc4ef0c7d9be0bf1d and easly clone it in your account. Enjoy and let us know of your results!

2 comments