The BigML team has been hard at work the past few months. While we haven’t figured out how to work more than 24 hours in a day, we think you’ll be pleased with the key features of BigML’s Spring Release.
First and foremost, we’re excited to announce Cluster Analysis, our first foray into unsupervised learning. Other key features in the Spring release include more filter and new field options, online dataset creation, major updates to BigMLer and more.

Clusters
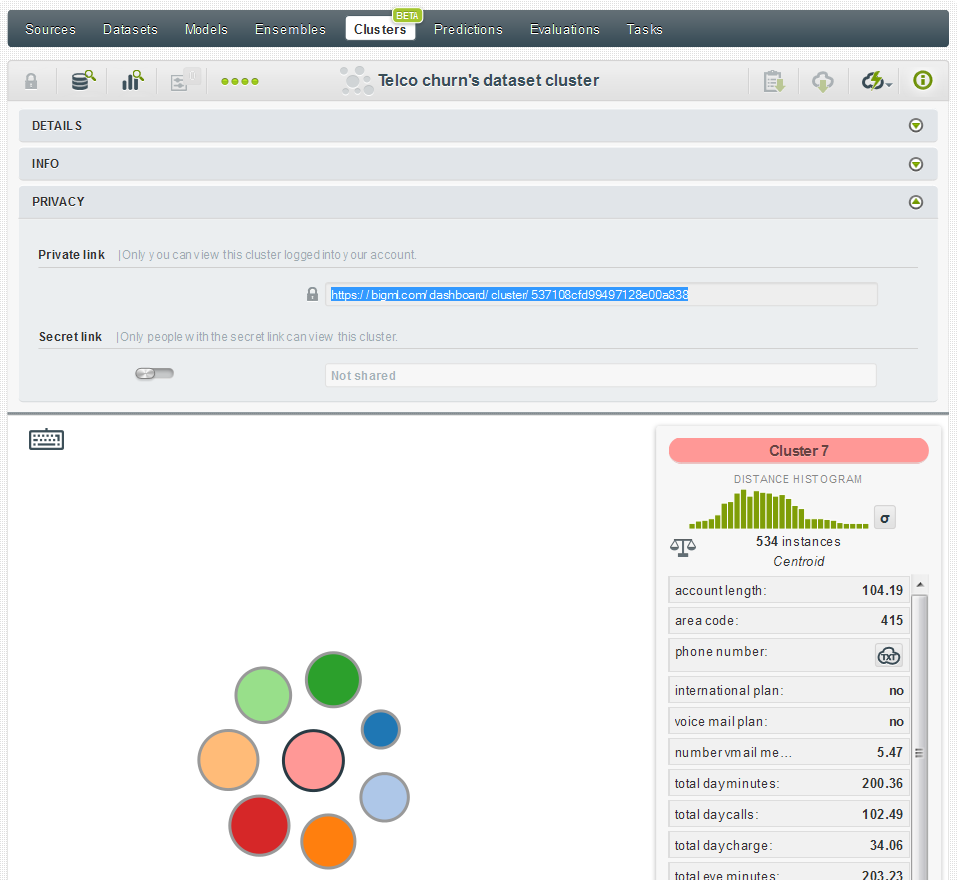
Now you can automatically group together the most similar instances in your dataset into different groups (i.e., clusters).
BigML’s clustering algorithm has been inspired by k-means, so you can select the number of groups to create (i.e., k) and also how each field in your dataset influences to which group each data point belongs (i.e., scales). Similar to our trees and ensembles, you can choose to create a cluster in only one click from your dataset. By default, BigML will create 8 clusters and we’ll apply automatic scaling to all the numeric fields, although the number of clusters as well as field scaling and weighting can be easily modified when you configure your cluster.
Scaling is very important as very often datasets will contain fields with very different magnitudes. For example, a demographics dataset might contain age and salary. If clustering is performed on those fields, salary will dominate the clusters while age is mostly ignored. Generally that’s not what you want when clustering, hence the auto-scale fields (balance_fields in the API) option. When auto-scale is enabled, all the numeric fields will be scaled so that their standard deviations are 1. This makes each field have roughly equivalent influence. You can also pick your own scale for each field.
Once you build a cluster you can use it to predict the centroid (i.e., find the closest centroid for a new data point) and also to create batch centroids in the same way batch predictions work.
Cluster Analysis has been released in Beta so please let us know if something does not work as expected or if think we’ve overlooked any helpful features.
By the way, you can also share clusters via private links in the same way you can share datasets or models:
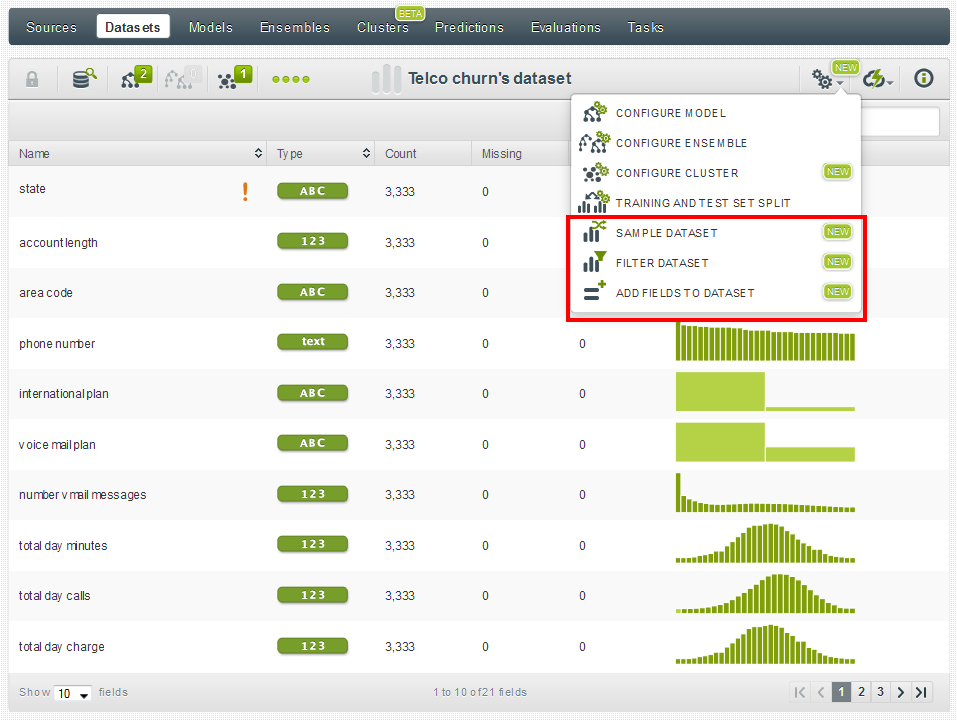
More Filter and New Field Options
In our Winter release we introduced Flatline—a Lisp-like language that can be used to filter rows of a dataset, and also to generate new fields using a mix of columns and rows. This language easily allows one to extend the number of filtering and new field creation options that BigML offers, and is now implemented in the BigML interface as part of our Spring Release. For example, you can now easily filter a dataset using different comparison, equality, missing value, and statistics functions. You can also create new fields discretizing, replacing missing fields, normalizing, and performing all kind of math transformations on previous values of your dataset. Have a look at the Filter Dataset and Add Field to Dataset options, and remember that you can also use Flatline to input any complex function that you might need.
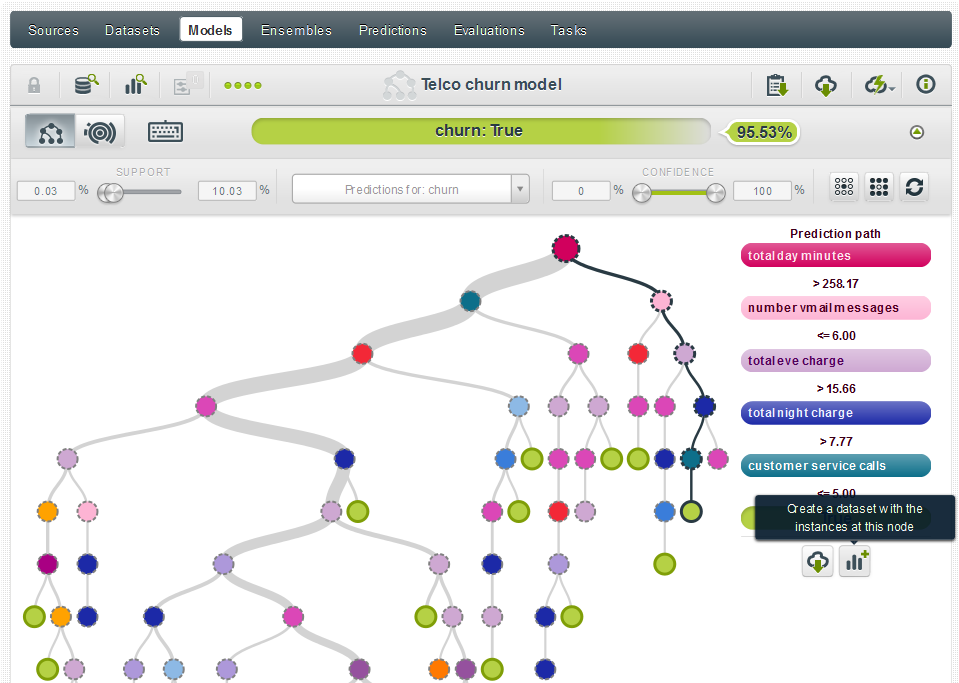
Segment-based dataset creation in models
Have you ever wanted to create a new dataset for further analysis from a specific node in a tree? Now you can! When you’re in a model or sunburst view, simply mouse over a node and then press your keyboard’s shift button. This will freeze the view and allow you to export the rules for that segment and/or create a new dataset with the instances at that node.
Dataset exports
Now you can also export datasets from a dataset view into a comma-separated values (CSV) file. This works very well in combination with the dataset creation above as it can help you identify the instances that follow certain criteria.

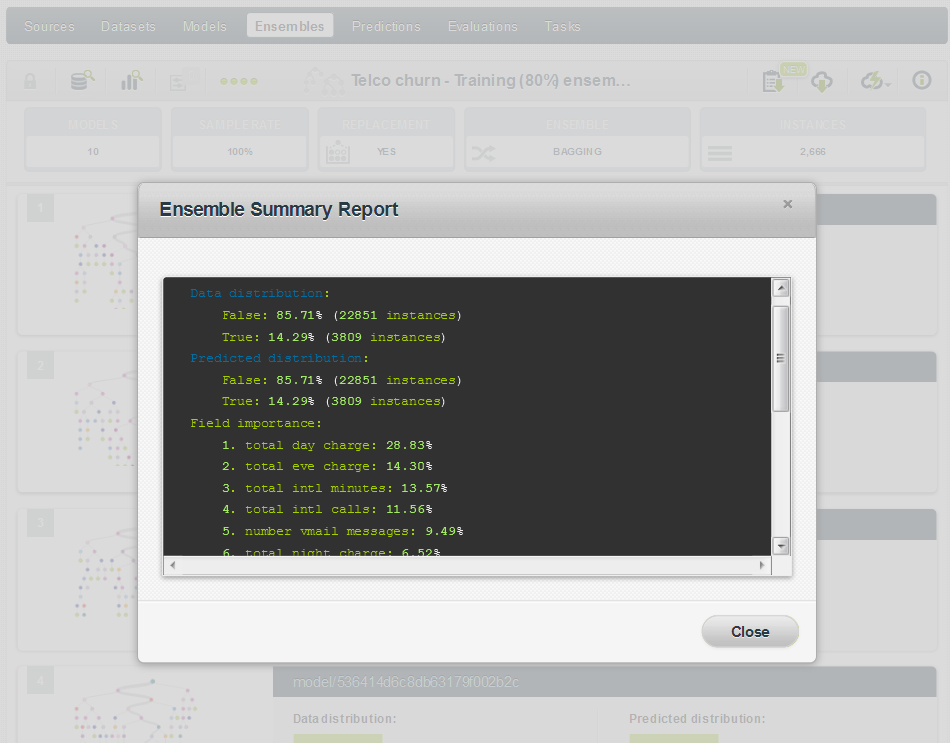
Ensemble Summary Report
A nifty (and perhaps underappreciated) feature of BigML is the ability to get a summary report of your model which shows your predicted data distribution, field importance and associated outcomes. You can now get a similar report for your Ensembles! This is a great way to get a quick summary on what fields have the greatest impact on your predictive outcome–something that can be very illustrative when working with new and/or wide datasets.
New BigMLer
BigMLer, our popular command line tool for machine learning, now features powerful new evaluation-guided techniques to support advanced predictive modeling. Specifically, through a new subcommand bigmler analyze you can quickly perform smart feature selection and node threshold selection. Feature selection detects the subset of features that will produce better models according to their evaluation measures (be it accuracy, phi or the one you like best). Node threshold selection finds out the number of nodes that your model should grow to in order to optimize evaluations. We’ll give you more details in an upcoming blog post.
And More..
There’s also a bunch of tiny small things like: directly log-in with Github, processing firebase URLs, and of course tons of improvements in our API, backend and infrastructure.
The Spring Release features are available immediately—simply log into your account and get started today! And be sure to let us know your feedback—we love hearing from our users and want to make sure that we continue to deliver the best machine learning platform possible.

Reblogged this on In Canada , things I learn daily and commented:
brilliant work– cluster analysis now available in BigML.com
Much awaited Clustering is here! Surely a massive growth from the day I tested and today!! Congrats guys!